publications
Recent key publications in reversed chronological order (* denotes co-first authorship)
2026
-
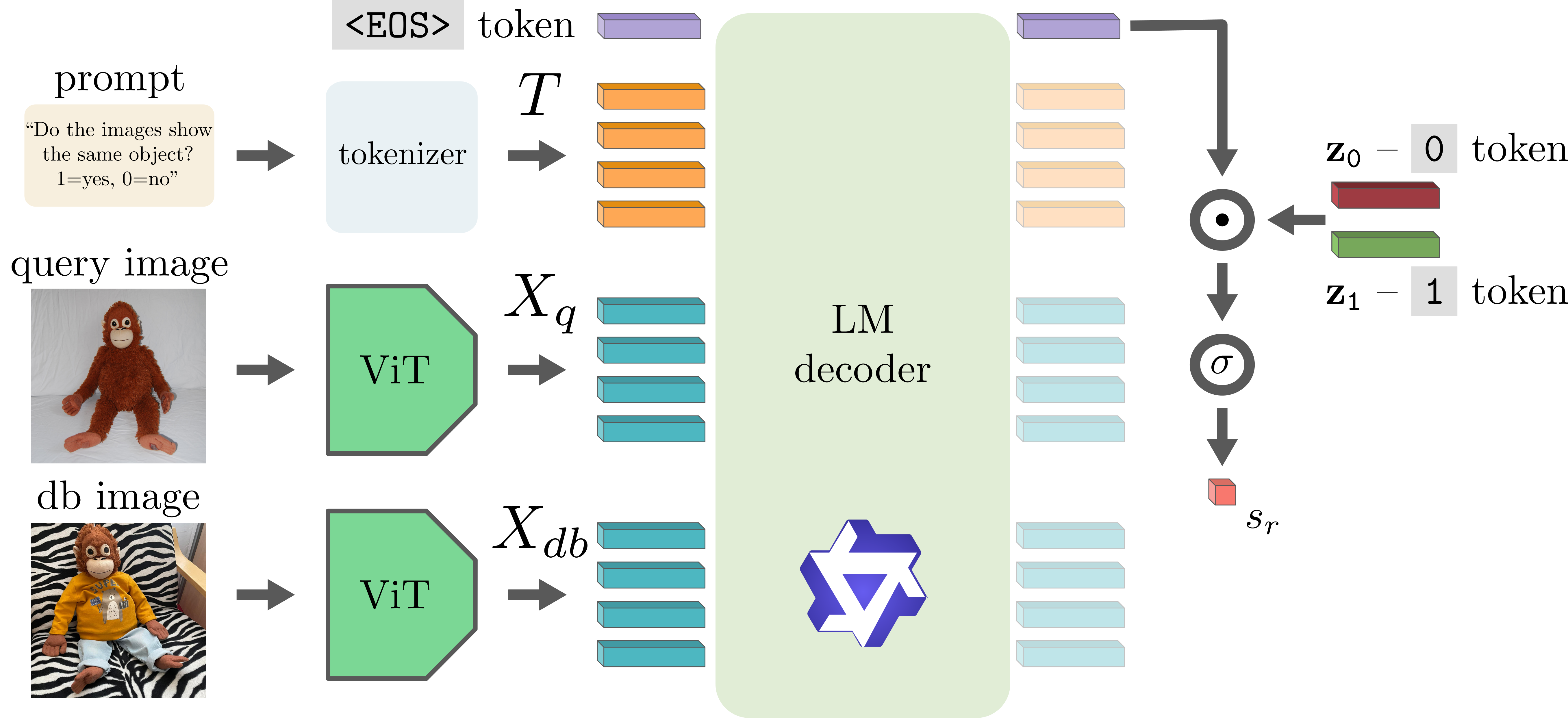 Indexing Multimodal Language Models for Large-scale Image RetrievalBahey Tharwat*, Giorgos Kordopatis-Zilos*, Pavel Suma, and 2 more authorsIn Computer Vision and Pattern Recognition (CVPR) Findings, 2026
Indexing Multimodal Language Models for Large-scale Image RetrievalBahey Tharwat*, Giorgos Kordopatis-Zilos*, Pavel Suma, and 2 more authorsIn Computer Vision and Pattern Recognition (CVPR) Findings, 2026Multimodal Large Language Models (MLLMs) have demonstrated strong cross-modal reasoning capabilities, yet their potential for vision-only tasks remains underexplored. We investigate MLLMs as training-free similarity estimators for instance-level image-to-image retrieval. Our approach prompts the model with paired images and converts next-token probabilities into similarity scores, enabling zero-shot re-ranking within large-scale retrieval pipelines. This design avoids specialized architectures and fine-tuning, leveraging the rich visual discrimination learned during multimodal pre-training. We address scalability by combining MLLMs with memory-efficient indexing and top-k candidate re-ranking. Experiments across diverse benchmarks show that MLLMs outperform task-specific re-rankers outside their native domains and exhibit superior robustness to clutter, occlusion, and small objects. Despite strong results, we identify failure modes under severe appearance changes, highlighting opportunities for future research. Our findings position MLLMs as a promising alternative for open-world large-scale image retrieval.
@inproceedings{tharwat2026mllm, title = {Indexing Multimodal Language Models for Large-scale Image Retrieval}, author = {Tharwat*, Bahey and Kordopatis-Zilos*, Giorgos and Suma, Pavel and Reid, Ian and Tolias, Giorgos}, booktitle = {Computer Vision and Pattern Recognition (CVPR) Findings}, year = {2026}, } -
 ELViS: Efficient Visual Similarity from Local Descriptors that Generalizes Across DomainsPavel Suma, Giorgos Kordopatis-Zilos, Yannis Kalantidis, and 1 more authorIn International Conference on Representation Learning (ICLR), 2026
ELViS: Efficient Visual Similarity from Local Descriptors that Generalizes Across DomainsPavel Suma, Giorgos Kordopatis-Zilos, Yannis Kalantidis, and 1 more authorIn International Conference on Representation Learning (ICLR), 2026Large-scale instance-level training data is scarce, so models are typically trained on domain-specific datasets. Yet in real-world retrieval, they must handle diverse domains, making generalization to unseen data critical. We introduce ELViS, an image-to-image similarity model that generalizes effectively to unseen domains. Unlike conventional approaches, our model operates in similarity space rather than representation space, promoting cross-domain transfer. It leverages local descriptor correspondences, refines their similarities through an optimal transport step with data-dependent gains that suppress uninformative descriptors, and aggregates strong correspondences via a voting process into an image-level similarity. This design injects strong inductive biases, yielding a simple, efficient, and interpretable model. To assess generalization, we compile a benchmark of eight datasets spanning landmarks, artworks, products, and multi-domain collections, and evaluate ELViS as a re-ranking method. Our experiments show that ELViS outperforms competing methods by a large margin in out-of-domain scenarios and on average, while requiring only a fraction of their computational cost.
@inproceedings{suma2026elvis, title = {ELViS: Efficient Visual Similarity from Local Descriptors that Generalizes Across Domains}, author = {Suma, Pavel and Kordopatis-Zilos, Giorgos and Kalantidis, Yannis and Tolias, Giorgos}, url = {https://openreview.net/forum?id=9nphGvSatt}, booktitle = {International Conference on Representation Learning (ICLR)}, year = {2026}, }


2025
-
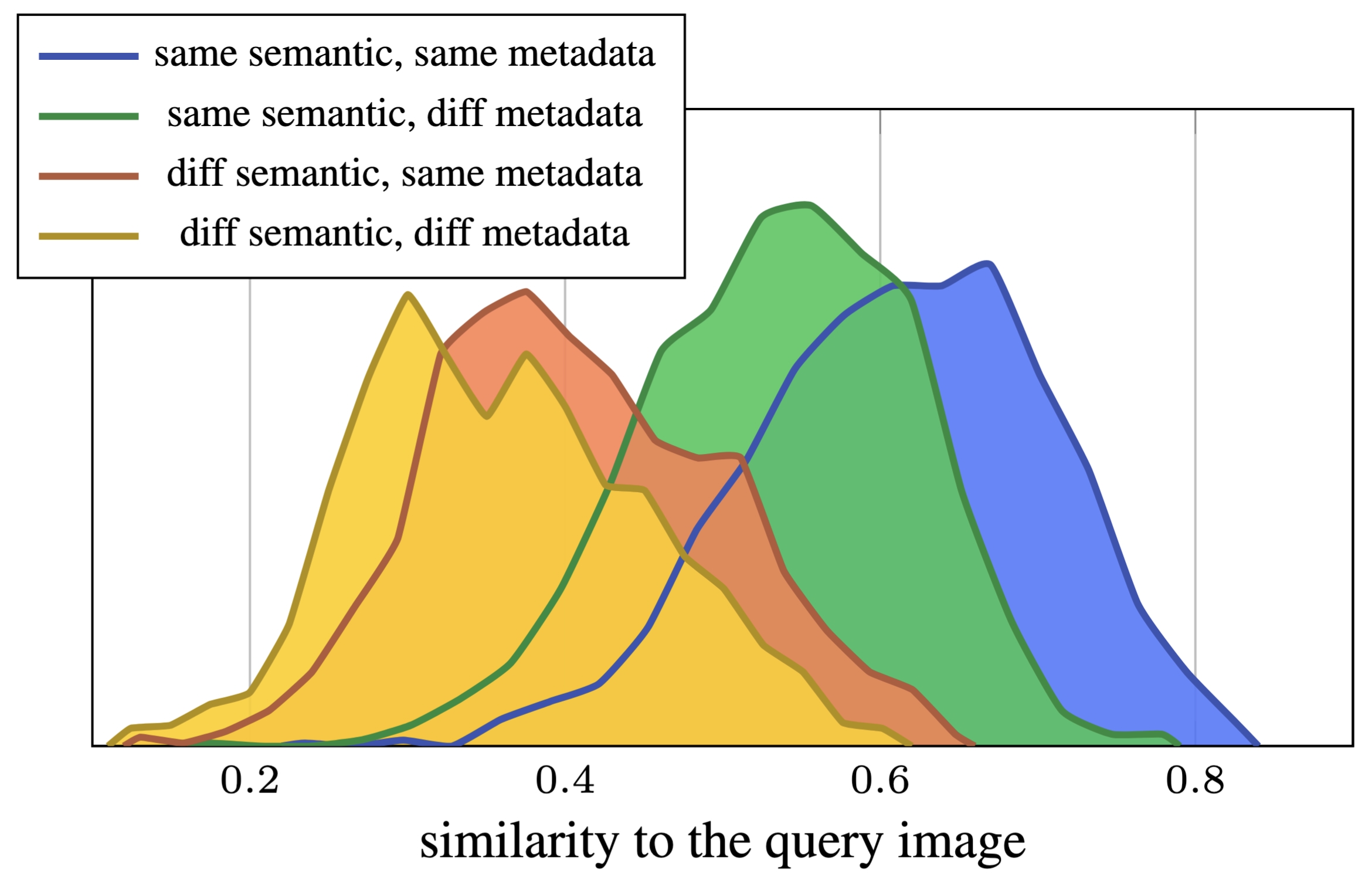 Processing and acquisition traces in visual encoders: What does CLIP know about your camera?Ryan Ramos, Vladan Stojnić, Giorgos Kordopatis-Zilos, and 3 more authorsIn International Conference on Computer Vision (ICCV), 2025
Processing and acquisition traces in visual encoders: What does CLIP know about your camera?Ryan Ramos, Vladan Stojnić, Giorgos Kordopatis-Zilos, and 3 more authorsIn International Conference on Computer Vision (ICCV), 2025Prior work has analyzed the robustness of visual encoders to image transformations and corruptions, particularly in cases where such alterations are not seen during training. When this occurs, they introduce a form of distribution shift at test time, often leading to performance degradation. The primary focus has been on severe corruptions that, when applied aggressively, distort useful signals necessary for accurate semantic predictions. We take a different perspective by analyzing parameters of the image acquisition process and transformations that may be subtle or even imperceptible to the human eye. We find that such parameters are systematically encoded in the learned visual representations and can be easily recovered. More strikingly, their presence can have a profound impact, either positively or negatively, on semantic predictions. This effect depends on whether there is a strong correlation or anti-correlation between semantic labels and these acquisition-based or processing-based labels. Our code and data are available at: https://github.com/ryan-caesar-ramos/visual-encoder-traces
@inproceedings{ramos2025bias, title = {Processing and acquisition traces in visual encoders: What does {CLIP} know about your camera?}, author = {Ramos, Ryan and Stojnić, Vladan and Kordopatis-Zilos, Giorgos and Nakashima, Yuta and Tolias, Giorgos and Garcia, Noa}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2025}, doi = {}, video = {https://www.youtube.com/watch?v=g1bpZjQjWDg} } -
 ILIAS: Instance-Level Image retrieval At ScaleGiorgos Kordopatis-Zilos, Vladan Stojnić, Anna Manko, and 7 more authorsIn Computer Vision and Pattern Recognition (CVPR), 2025
ILIAS: Instance-Level Image retrieval At ScaleGiorgos Kordopatis-Zilos, Vladan Stojnić, Anna Manko, and 7 more authorsIn Computer Vision and Pattern Recognition (CVPR), 2025This work introduces ILIAS, a new test dataset for Instance-Level Image retrieval At Scale. It is designed to evaluate the ability of current and future foundation models and retrieval techniques to recognize particular objects. The key benefits over existing datasets include large scale, domain diversity, accurate ground truth, and a performance that is far from saturated. ILIAS includes query and positive images for 1,000 object instances, manually collected to capture challenging conditions and diverse domains. Large-scale retrieval is conducted against 100 million distractor images from YFCC100M. To avoid false negatives without extra annotation effort, we include only query objects confirmed to have emerged after 2014, i.e. the compilation date of YFCC100M. An extensive benchmarking is performed with the following observations: i) models fine-tuned on specific domains, such as landmarks or products, excel in that domain but fail on ILIAS ii) learning a linear adaptation layer using multi-domain class supervision results in performance improvements, especially for vision-language models iii) local descriptors in retrieval re-ranking are still a key ingredient, especially in the presence of severe background clutter iv) the text-to-image performance of the vision-language foundation models is surprisingly close to the corresponding image-to-image case.
@inproceedings{kordopatis2025ilias, title = {{ILIAS}: Instance-Level Image retrieval At Scale}, author = {Kordopatis-Zilos, Giorgos and Stojnić, Vladan and Manko, Anna and Šuma, Pavel and Ypsilantis, Nikolaos-Antonios and Efthymiadis, Nikos and Laskar, Zakaria and Matas, Jiří and Chum, Ondřej and Tolias, Giorgos}, booktitle = {Computer Vision and Pattern Recognition (CVPR)}, year = {2025}, doi = {10.1109/CVPR52734.2025.01377} } -
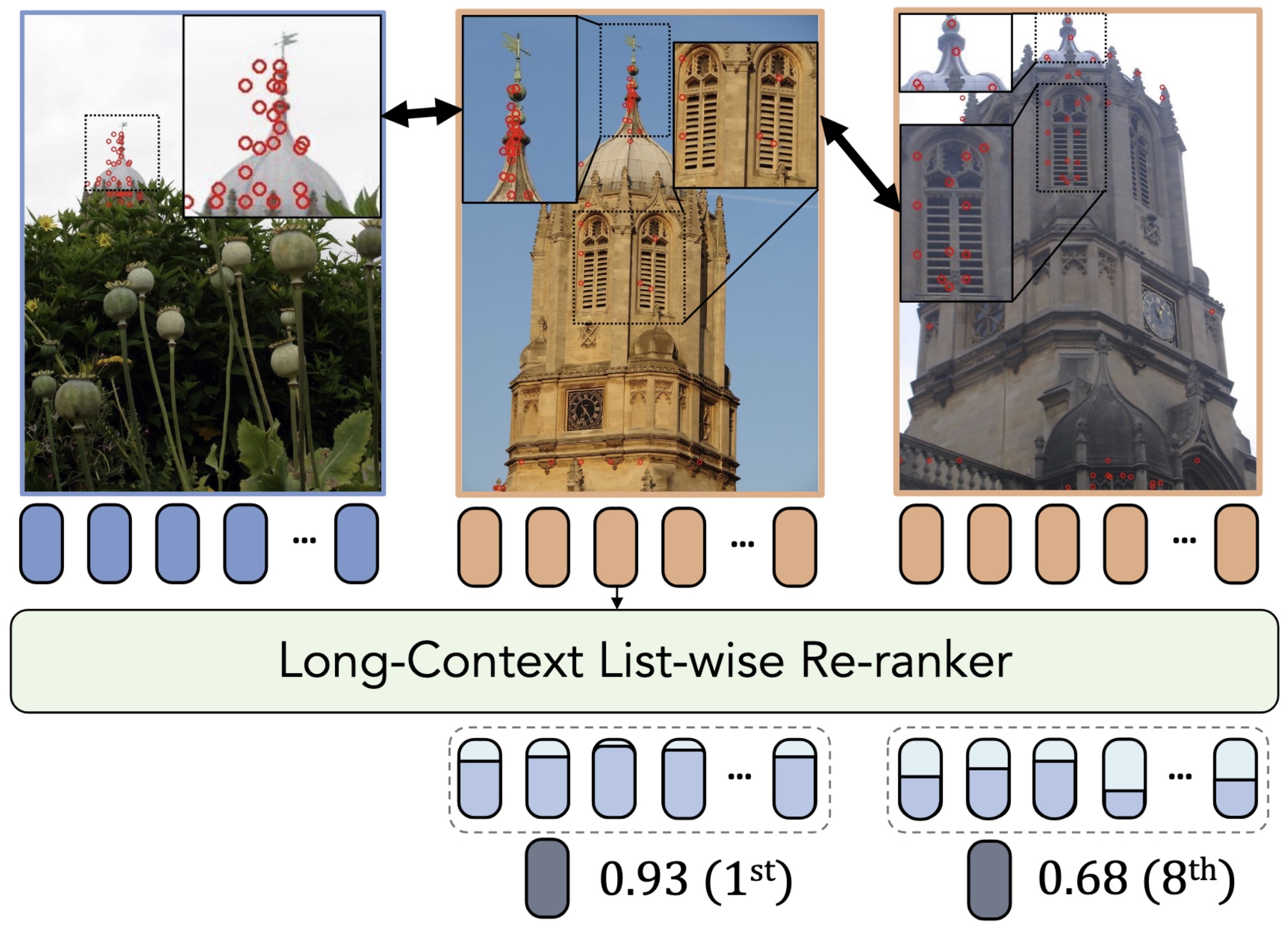 LoCoRe: Image Re-ranking with Long-Context Sequence ModelingZilin Xiao, Pavel Suma, Ayush Sachdeva, and 4 more authorsIn Computer Vision and Pattern Recognition (CVPR), 2025
LoCoRe: Image Re-ranking with Long-Context Sequence ModelingZilin Xiao, Pavel Suma, Ayush Sachdeva, and 4 more authorsIn Computer Vision and Pattern Recognition (CVPR), 2025We introduce LoCoRe, Long-Context Re-ranker, a model that takes as input local descriptors corresponding to an image query and a list of gallery images and outputs similarity scores between the query and each gallery image. This model is used for image retrieval, where typically a first ranking is performed with an efficient similarity measure, and then a shortlist of top-ranked images is re-ranked based on a more fine-grained similarity measure. Compared to existing methods that perform pair-wise similarity estimation with local descriptors or list-wise re-ranking with global descriptors, LoCoRe is the first method to perform list-wise re-ranking with local descriptors. To achieve this, we leverage efficient long-context sequence models to effectively capture the dependencies between query and gallery images at the local-descriptor level. During testing, we process long shortlists with a sliding window strategy that is tailored to overcome the context size limitations of sequence models. Our approach achieves superior performance compared with other re-rankers on established image retrieval benchmarks of landmarks (ROxf and RPar), products (SOP), fashion items (In-Shop), and bird species (CUB-200) while having comparable latency to the pair-wise local descriptor re-rankers.
@inproceedings{xiao2025locore, title = {{LoCoRe}: Image Re-ranking with Long-Context Sequence Modeling}, author = {Xiao, Zilin and Suma, Pavel and Sachdeva, Ayush and Wang, Hao-Jen and Kordopatis-Zilos, Giorgos and Tolias, Giorgos and Ordonez, Vicente}, booktitle = {Computer Vision and Pattern Recognition (CVPR)}, year = {2025}, video = {https://www.youtube.com/watch?v=3CcA70RBfIE}, doi = {10.1109/CVPR52734.2025.00895} } -
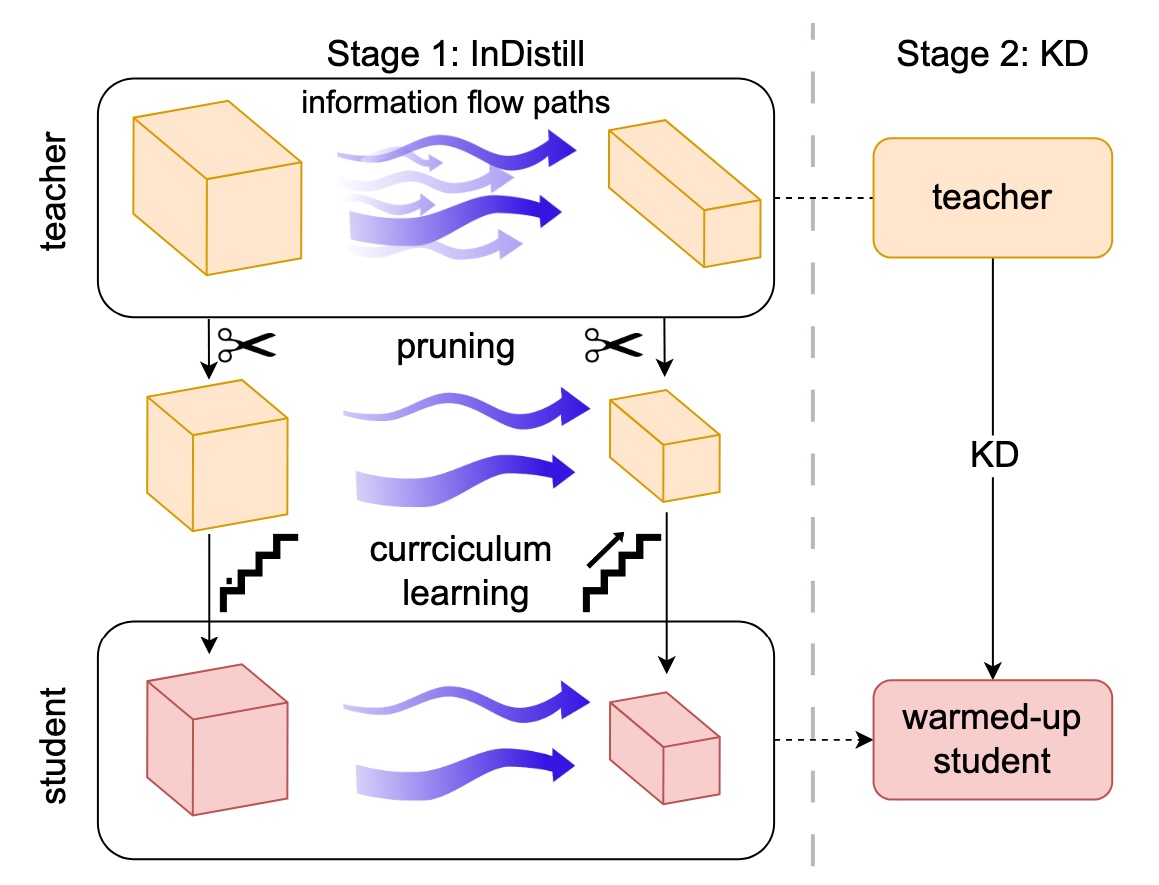 InDistill: Information flow-preserving knowledge distillation for model compressionIoannis Sarridis, Christos Koutlis, Giorgos Kordopatis-Zilos, and 2 more authorsIn Winter Conference on Applications of Computer Vision (WACV), 2025
InDistill: Information flow-preserving knowledge distillation for model compressionIoannis Sarridis, Christos Koutlis, Giorgos Kordopatis-Zilos, and 2 more authorsIn Winter Conference on Applications of Computer Vision (WACV), 2025In this paper, we introduce InDistill, a method that serves as a warmup stage for enhancing Knowledge Distillation (KD) effectiveness. InDistill focuses on transferring critical information flow paths from a heavyweight teacher to a lightweight student. This is achieved via a training scheme based on curriculum learning that considers the distillation difficulty of each layer and the critical learning periods when the information flow paths are established. This procedure can lead to a student model that is better prepared to learn from the teacher. To ensure the applicability of InDistill across a wide range of teacher-student pairs, we also incorporate a pruning operation when there is a discrepancy in the width of the teacher and student layers. This pruning operation reduces the width of the teacher’s intermediate layers to match those of the student, allowing direct distillation without the need for an encoding stage. The proposed method is extensively evaluated using various pairs of teacher-student architectures on CIFAR-10, CIFAR-100, and ImageNet datasets demonstrating that preserving the information flow paths consistently increases the performance of the baseline KD approaches on both classification and retrieval settings.
@inproceedings{sarridis2025indistill, title = {{InDistill}: Information flow-preserving knowledge distillation for model compression}, author = {Sarridis, Ioannis and Koutlis, Christos and Kordopatis-Zilos, Giorgos and Kompatsiaris, Ioannis and Papadopoulos, Symeon}, booktitle = {Winter Conference on Applications of Computer Vision (WACV)}, year = {2025}, doi = {10.1109/WACV61041.2025.00875} }




2024
-
 AMES: Asymmetric and Memory-Efficient Similarity Estimation for Instance-level RetrievalPavel Suma, Giorgos Kordopatis-Zilos, Ahmet Iscen, and 1 more authorIn European Conference on Computer Vision (ECCV), 2024
AMES: Asymmetric and Memory-Efficient Similarity Estimation for Instance-level RetrievalPavel Suma, Giorgos Kordopatis-Zilos, Ahmet Iscen, and 1 more authorIn European Conference on Computer Vision (ECCV), 2024This work investigates the problem of instance-level image retrieval re-ranking with the constraint of memory efficiency, ultimately aiming to limit memory usage to 1KB per image. Departing from the prevalent focus on performance enhancements, this work prioritizes the crucial trade-off between performance and memory requirements. The proposed model uses a transformer-based architecture designed to estimate image-to-image similarity by capturing interactions within and across images based on their local descriptors. A distinctive property of the model is the capability for asymmetric similarity estimation. Database images are represented with a smaller number of descriptors compared to query images, enabling performance improvements without increasing memory consumption. To ensure adaptability across different applications, a universal model is introduced that adjusts to a varying number of local descriptors during the testing phase. Results on standard benchmarks demonstrate the superiority of our approach over both hand-crafted and learned models. In particular, compared with current state-of-the-art methods that overlook their memory footprint, our approach not only attains superior performance but does so with a significantly reduced memory footprint. The code and pretrained models are publicly available at: https://github.com/pavelsuma/ames
@inproceedings{suma2024ames, title = {{AMES}: Asymmetric and Memory-Efficient Similarity Estimation for Instance-level Retrieval}, author = {Suma, Pavel and Kordopatis-Zilos, Giorgos and Iscen, Ahmet and Tolias, Giorgos}, booktitle = {European Conference on Computer Vision (ECCV)}, url = {https://link.springer.com/chapter/10.1007/978-3-031-73202-7_18}, year = {2024}, doi = {10.1007/978-3-031-73202-7_18} } -
 MINTIME: Multi-Identity Size-Invariant Video Deepfake DetectionDavide Alessandro Coccomini, Giorgos Kordopatis-Zilos, Giuseppe Amato, and 4 more authorsIn IEEE Transactions on Information Forensics and Security (TIFS), 2024
MINTIME: Multi-Identity Size-Invariant Video Deepfake DetectionDavide Alessandro Coccomini, Giorgos Kordopatis-Zilos, Giuseppe Amato, and 4 more authorsIn IEEE Transactions on Information Forensics and Security (TIFS), 2024In this paper, we present MINTIME, a video deepfake detection method that effectively captures spatial and temporal inconsistencies in videos that depict multiple individuals and varying face sizes. Unlike previous approaches that either employ simplistic a-posteriori aggregation schemes, i.e., averaging or max operations, or only focus on the largest face in the video, our proposed method learns to accurately detect spatio-temporal inconsistencies across multiple identities in a video through a Spatio-Temporal Transformer combined with a Convolutional Neural Network backbone. This is achieved through an Identity-aware Attention mechanism that applies a masking operation on the face sequence to process each identity independently, which enables effective video-level aggregation. Furthermore, our system incorporates two novel embedding schemes: (i) the Temporal Coherent Positional Embedding, which encodes the temporal information of the face sequences of each identity, and (ii) the Size Embedding, which captures the relative sizes of the faces to the video frames. MINTIME achieves state-of-the-art performance on the ForgeryNet dataset, with a remarkable improvement of up to 14% AUC in videos containing multiple people. Moreover, it demonstrates very robust generalization capabilities in cross-forgery and cross-dataset settings. The code is publicly available at: https://github.com/davide-coccomini/MINTIME-Multi-Identity-size-iNvariant-TIMEsformer-for-Video-Deepfake-Detection
@inproceedings{coccomini2024mintime, title = {{MINTIME}: Multi-Identity Size-Invariant Video Deepfake Detection}, author = {Coccomini, Davide Alessandro and Kordopatis-Zilos, Giorgos and Amato, Giuseppe and Caldelli, Roberto and Falchi, Fabrizio and Papadopoulos, Symeon and Gennaro, Claudio}, booktitle = {IEEE Transactions on Information Forensics and Security (TIFS)}, year = {2024}, url = {https://ieeexplore.ieee.org/document/10547206}, doi = {10.1109/TIFS.2024.3409054} } -
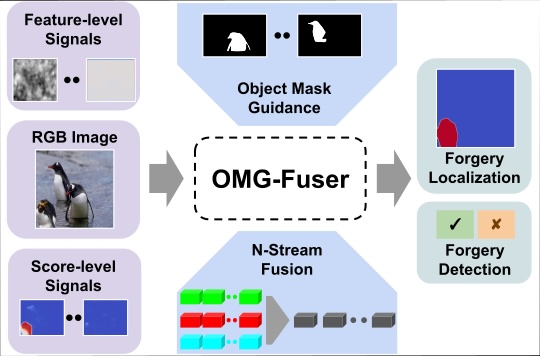 Fusion Transformer with Object Mask Guidance for Image Forgery AnalysisDimitrios Karageorgiou, Giorgos Kordopatis-Zilos, and Symeon PapadopoulosIn Computer Vision and Pattern Recognition Workshops (CVPRW), 2024
Fusion Transformer with Object Mask Guidance for Image Forgery AnalysisDimitrios Karageorgiou, Giorgos Kordopatis-Zilos, and Symeon PapadopoulosIn Computer Vision and Pattern Recognition Workshops (CVPRW), 2024In this work, we introduce OMG-Fuser, a fusion transformer-based network designed to extract information from various forensic signals to enable robust image forgery detection and localization. Our approach can operate with an arbitrary number of forensic signals and leverages object information for their analysis – unlike previous methods that rely on fusion schemes with few signals and often disregard image semantics. To this end, we design a forensic signal stream composed of a transformer guided by an object attention mechanism, associating patches that depict the same objects. In that way, we incorporate object-level information from the image. Each forensic signal is processed by a different stream that adapts to its peculiarities. A token fusion transformer efficiently aggregates the outputs of an arbitrary number of network streams and generates a fused representation for each image patch. We assess two fusion variants on top of the proposed approach: (i) score-level fusion that fuses the outputs of multiple image forensics algorithms and (ii) feature-level fusion that fuses low-level forensic traces directly. Both variants exceed state-of-the-art performance on seven datasets for image forgery detection and localization, with a relative average improvement of 12.1% and 20.4% in terms of F1. Our model is robust against traditional and novel forgery attacks and can be expanded with new signals without training from scratch. Our code is publicly available at: https://github.com/mever-team/omgfuser
@inproceedings{karageorgiou2024omg, title = {Fusion Transformer with Object Mask Guidance for Image Forgery Analysis}, author = {Karageorgiou, Dimitrios and Kordopatis-Zilos, Giorgos and Papadopoulos, Symeon}, booktitle = {Computer Vision and Pattern Recognition Workshops (CVPRW)}, url = {https://openaccess.thecvf.com/content/CVPR2024W/WMF/papers/Karageorgiou_Fusion_Transformer_with_Object_Mask_Guidance_for_Image_Forgery_Analysis_CVPRW_2024_paper.pdf}, year = {2024}, doi = {10.1109/CVPRW63382.2024.00438} } -
 The 2023 video similarity dataset and challengeEd Pizzi, Giorgos Kordopatis-Zilos, Hiral Patel, and 6 more authorsIn Computer Vision and Image Understanding (CVIU), 2024
The 2023 video similarity dataset and challengeEd Pizzi, Giorgos Kordopatis-Zilos, Hiral Patel, and 6 more authorsIn Computer Vision and Image Understanding (CVIU), 2024This work introduces a dataset, benchmark, and challenge for the problem of video copy tracing. There are two related tasks: determining whether a query video shares content with a reference video ("detection") and temporally localizing the shared content within each video ("localization"). The benchmark is designed to evaluate methods on these two tasks. It simulates a realistic needle-in-haystack setting, where the majority of both query and reference videos are "distractors" containing no copied content. We propose an accuracy metric for both tasks. The associated challenge imposes computing resource restrictions that reflect real-world settings. We also analyze the results and methods of the top submissions to the challenge. The dataset, baseline methods, and evaluation code are publicly available and were discussed at the Visual Copy Detection Workshop (VCDW) at CVPR’23. We provide reference code for evaluation and baselines at: https://github.com/facebookresearch/vsc2022.
@inproceedings{pizzi2024vsc, title = {The 2023 video similarity dataset and challenge}, author = {Pizzi, Ed and Kordopatis-Zilos, Giorgos and Patel, Hiral and Postelnicu, Gheorghe and Ravindra, Sugosh Nagavara and Gupta, Akshay and Papadopoulos, Symeon and Tolias, Giorgos and Douze, Matthijs}, booktitle = {Computer Vision and Image Understanding (CVIU)}, year = {2024}, url = {https://www.sciencedirect.com/science/article/pii/S107731422400078X}, video = {}, doi = {10.1016/j.cviu.2024.103997} }




2023
-
 Test-time Training for Matching-based Video Object SegmentationJuliette Bertrand*, Giorgos Kordopatis-Zilos*, Yannis Kalantidis, and 1 more authorIn Advances in Neural Information Processing Systems (NeurIPS) [* denotes co-first authorship], 2023
Test-time Training for Matching-based Video Object SegmentationJuliette Bertrand*, Giorgos Kordopatis-Zilos*, Yannis Kalantidis, and 1 more authorIn Advances in Neural Information Processing Systems (NeurIPS) [* denotes co-first authorship], 2023The video object segmentation (VOS) task involves the segmentation of an object over time based on a single initial mask. Current state-of-the-art approaches use a memory of previously processed frames and rely on matching to estimate segmentation masks of subsequent frames. Lacking any adaptation mechanism, such methods are prone to test-time distribution shifts. This work focuses on matching-based VOS under distribution shifts such as video corruptions, stylization, and sim-to-real transfer. We explore test-time training strategies that are agnostic to the specific task as well as strategies that are designed specifically for VOS. This includes a variant based on mask cycle consistency tailored to matching-based VOS methods. The experimental results on common benchmarks demonstrate that the proposed test-time training yields significant improvements in performance. In particular for the sim-to-real scenario and despite using only a single test video, our approach manages to recover a substantial portion of the performance gain achieved through training on real videos. Additionally, we introduce DAVIS-C, an augmented version of the popular DAVIS test set, featuring extreme distribution shifts like image-/video-level corruptions and stylizations. Our results illustrate that test-time training enhances performance even in these challenging cases.
@inproceedings{bertrand2023ttt, title = {Test-time Training for Matching-based Video Object Segmentation}, author = {Bertrand*, Juliette and Kordopatis{-}Zilos*, Giorgos and Kalantidis, Yannis and Tolias, Giorgos}, booktitle = {Advances in Neural Information Processing Systems (NeurIPS) [* denotes co-first authorship]}, year = {2023}, url = {https://openreview.net/forum?id=9QsdPQlWiE}, video = {https://neurips.cc/virtual/2023/poster/72598} } -
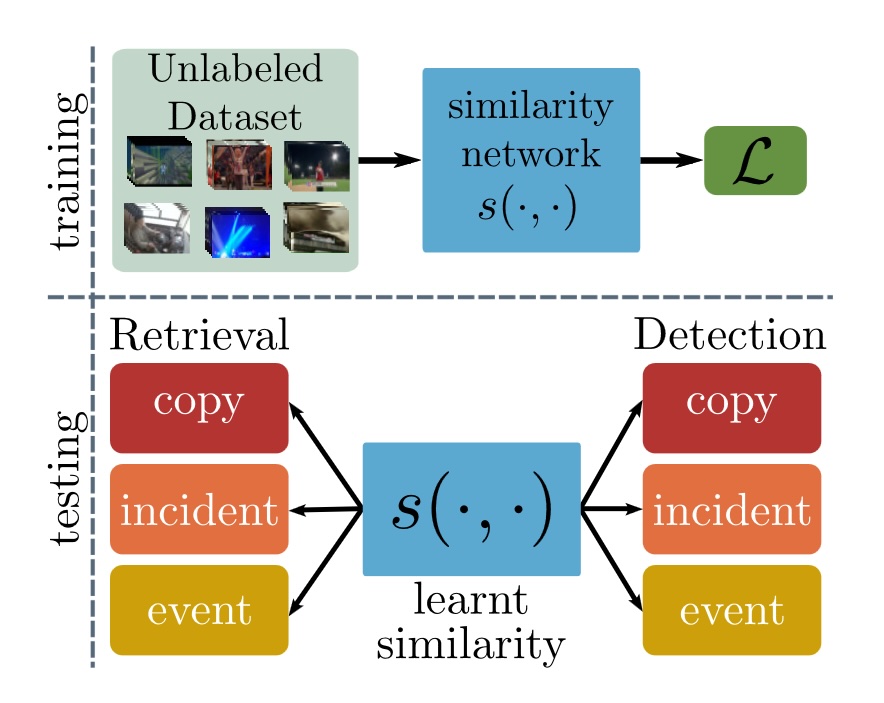 Self-Supervised Video Similarity LearningGiorgos Kordopatis-Zilos, Giorgos Tolias, Christos Tzelepis, and 3 more authorsIn Computer Vision and Pattern Recognition Workshops (CVPRW), 2023
Self-Supervised Video Similarity LearningGiorgos Kordopatis-Zilos, Giorgos Tolias, Christos Tzelepis, and 3 more authorsIn Computer Vision and Pattern Recognition Workshops (CVPRW), 2023We introduce S^2VS, a video similarity learning approach with self-supervision. Self-Supervised Learning (SSL) is typically used to train deep models on a proxy task so as to have strong transferability on target tasks after fine-tuning. Here, in contrast to prior work, SSL is used to perform video similarity learning and address multiple retrieval and detection tasks at once with no use of labeled data. This is achieved by learning via instance-discrimination with task-tailored augmentations and the widely used InfoNCE loss together with an additional loss operating jointly on self-similarity and hard-negative similarity. We benchmark our method on tasks where video relevance is defined with varying granularity, ranging from video copies to videos depicting the same incident or event. We learn a single universal model that achieves state-of-the-art performance on all tasks, surpassing previously proposed methods that use labeled data.
@inproceedings{kordopatis2023s2vs, title = {Self-Supervised Video Similarity Learning}, author = {Kordopatis{-}Zilos, Giorgos and Tolias, Giorgos and Tzelepis, Christos and Kompatsiaris, Ioannis and Patras, Ioannis and Papadopoulos, Symeon}, booktitle = {Computer Vision and Pattern Recognition Workshops (CVPRW)}, year = {2023}, doi = {10.1109/CVPRW59228.2023.00504} } -
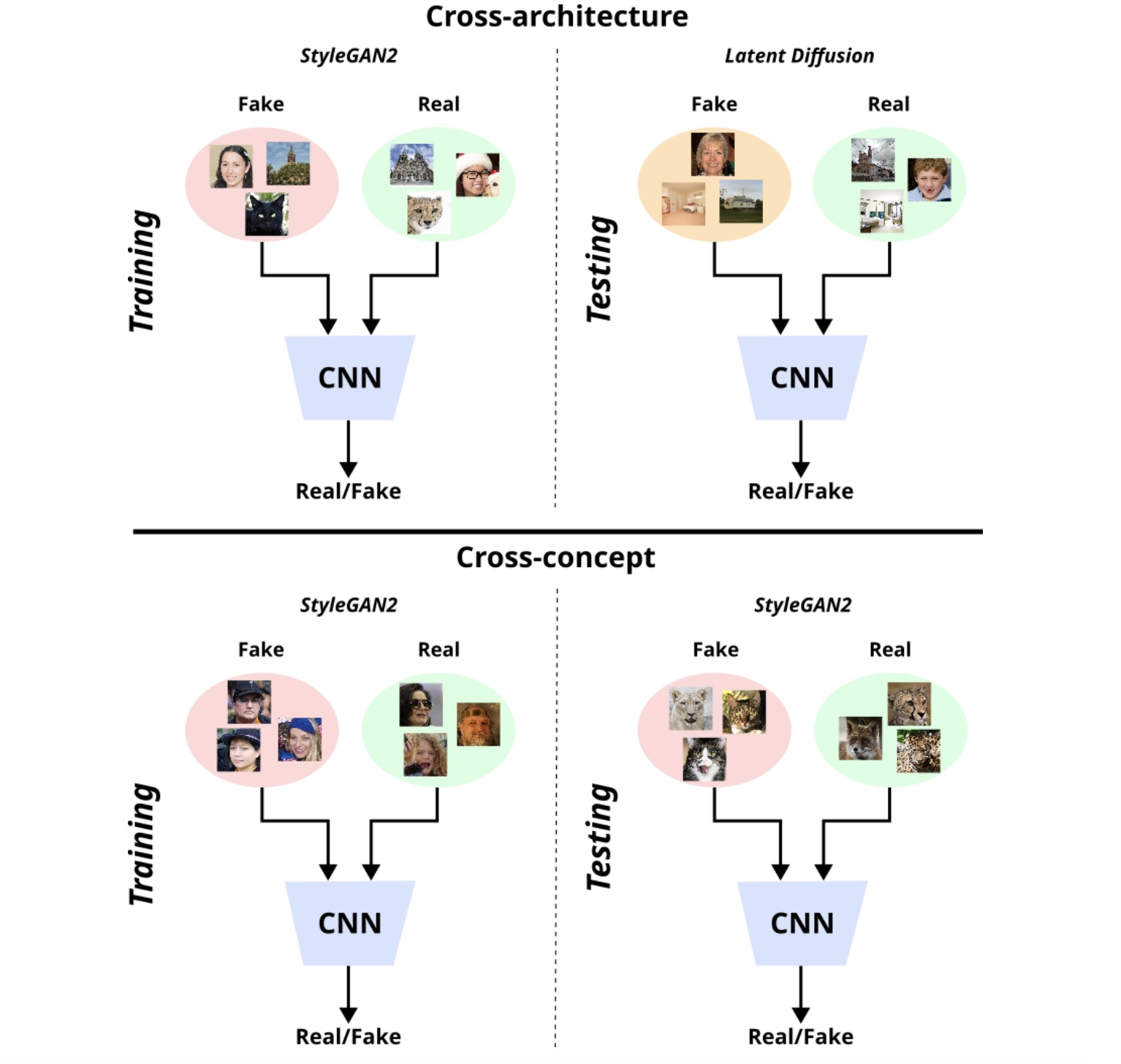 Improving Synthetically Generated Image Detection in Cross-Concept SettingsPantelis Dogoulis, Giorgos Kordopatis-Zilos, Ioannis Kompatsiaris, and 1 more authorIn International Workshop on Multimedia AI against Disinformation (MAD) @ICMR, 2023
Improving Synthetically Generated Image Detection in Cross-Concept SettingsPantelis Dogoulis, Giorgos Kordopatis-Zilos, Ioannis Kompatsiaris, and 1 more authorIn International Workshop on Multimedia AI against Disinformation (MAD) @ICMR, 2023New advancements for the detection of synthetic images are critical for fighting disinformation, as the capabilities of generative AI models continuously evolve and can lead to hyper-realistic synthetic imagery at unprecedented scale and speed. In this paper, we focus on the challenge of generalizing across different concept classes, e.g., when training a detector on human faces and testing on synthetic animal images - highlighting the ineffectiveness of existing approaches that randomly sample generated images to train their models. By contrast, we propose an approach based on the premise that the robustness of the detector can be enhanced by training it on realistic synthetic images that are selected based on their quality scores according to a probabilistic quality estimation model. We demonstrate the effectiveness of the proposed approach by conducting experiments with generated images from two seminal architectures, StyleGAN2 and Latent Diffusion, and using three different concepts for each, so as to measure the cross-concept generalization ability. Our results show that our quality-based sampling method leads to higher detection performance for nearly all concepts, improving the overall effectiveness of the synthetic image detectors.
@inproceedings{dogoulis2023qcsgid, title = {Improving Synthetically Generated Image Detection in Cross-Concept Settings}, author = {Dogoulis, Pantelis and Kordopatis{-}Zilos, Giorgos and Kompatsiaris, Ioannis and Papadopoulos, Symeon}, booktitle = {International Workshop on Multimedia AI against Disinformation (MAD) @ICMR}, year = {2023}, doi = {10.1145/3592572.3592846} }



2022
-
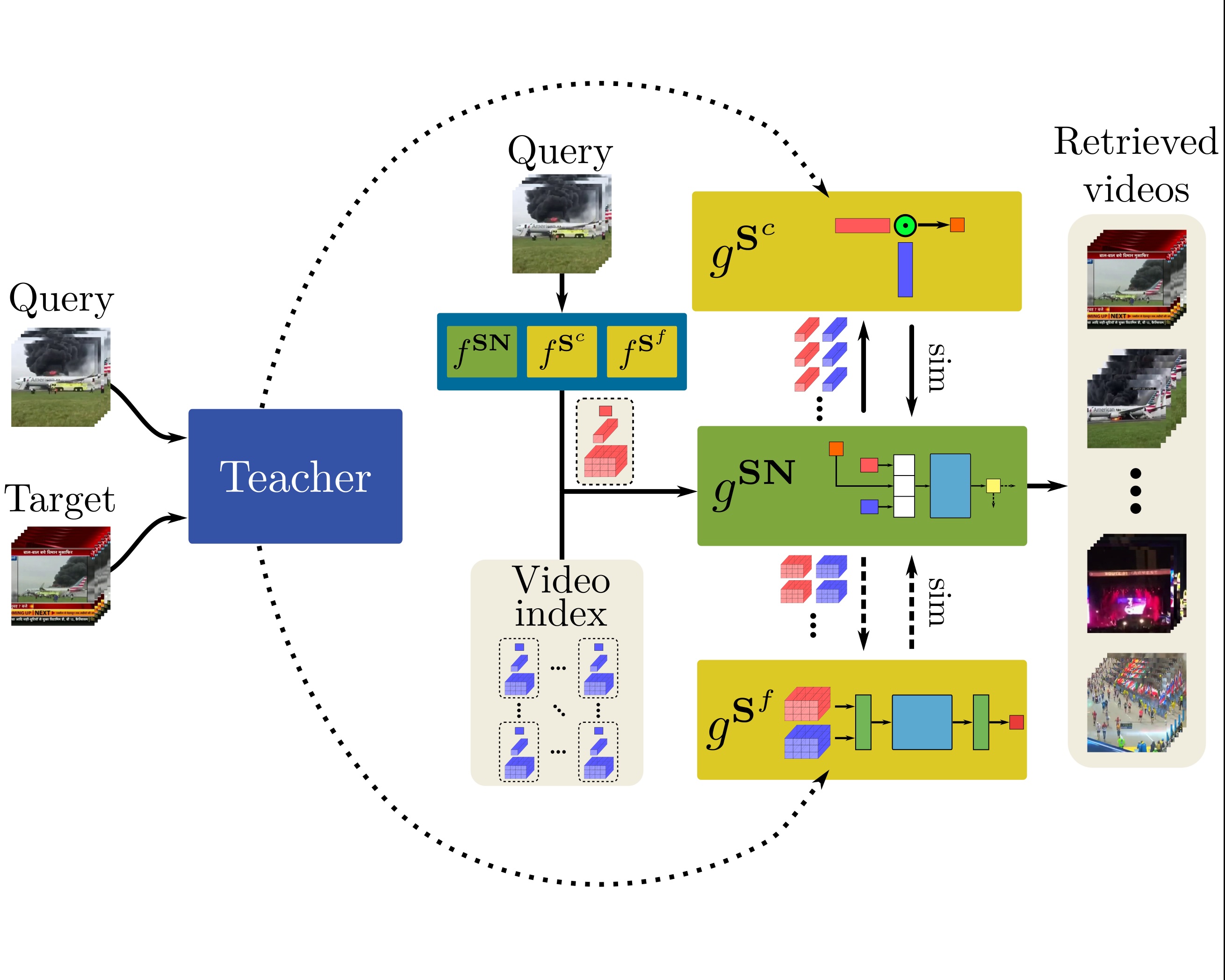 DnS: Distill-and-Select for Efficient and Accurate Video Indexing and RetrievalGiorgos Kordopatis-Zilos, Christos Tzelepis, Symeon Papadopoulos, and 2 more authorsInternational Journal of Computer Vision (IJCV), 2022
DnS: Distill-and-Select for Efficient and Accurate Video Indexing and RetrievalGiorgos Kordopatis-Zilos, Christos Tzelepis, Symeon Papadopoulos, and 2 more authorsInternational Journal of Computer Vision (IJCV), 2022In this paper, we address the problem of high performance and computationally efficient content-based video retrieval in large-scale datasets. Current methods typically propose either: (i) fine-grained approaches employing spatio-temporal representations and similarity calculations, achieving high performance at a high computational cost or (ii) coarse-grained approaches representing/indexing videos as global vectors, where the spatio-temporal structure is lost, providing low performance but also having low computational cost. In this work, we propose a Knowledge Distillation framework, called Distill-and-Select (DnS), that starting from a well-performing fine-grained Teacher Network learns: a) Student Networks at different retrieval performance and computational efficiency trade-offs and b) a Selector Network that at test time rapidly directs samples to the appropriate student to maintain both high retrieval performance and high computational efficiency. We train several students with different architectures and arrive at different trade-offs of performance and efficiency, i.e., speed and storage requirements, including fine-grained students that store/index videos using binary representations. Importantly, the proposed scheme allows Knowledge Distillation in large, unlabelled datasets – this leads to good students. We evaluate DnS on five public datasets on three different video retrieval tasks and demonstrate a) that our students achieve state-of-the-art performance in several cases and b) that the DnS framework provides an excellent trade-off between retrieval performance, computational speed, and storage space. In specific configurations, the proposed method achieves similar mAP with the teacher but is 20 times faster and requires 240 times less storage space. The collected dataset and implementation are publicly available at https://github.com/mever-team/distill-and-select.
@article{kordopatis2022dns, title = {{DnS}: Distill-and-Select for Efficient and Accurate Video Indexing and Retrieval}, author = {Kordopatis{-}Zilos, Giorgos and Tzelepis, Christos and Papadopoulos, Symeon and Kompatsiaris, Ioannis and Patras, Ioannis}, journal = {International Journal of Computer Vision (IJCV)}, volume = {130}, number = {10}, pages = {2385--2407}, year = {2022}, doi = {10.1007/s11263-022-01651-3}, } -
 Leveraging Selective Prediction for Reliable Image GeolocationGiorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and 1 more authorIn International Conference on Multimedia Modeling (MMM), 2022
Leveraging Selective Prediction for Reliable Image GeolocationGiorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and 1 more authorIn International Conference on Multimedia Modeling (MMM), 2022Reliable image geolocation is crucial for several applications, ranging from social media geo-tagging to media verification. State-of-the-art geolocation methods surpass human performance on the task of geolocation estimation from images. However, no method assesses the suitability of an image for this task, which results in unreliable and erroneous estimations for images containing ambiguous or no geolocation clues. In this paper, we define the task of image localizability, i.e. suitability of an image for geolocation, and propose a selective prediction methodology to address the task. In particular, we propose two novel selection functions that leverage the output probability distributions of geolocation models to infer localizability at different scales. Our selection functions are benchmarked against the most widely used selective prediction baselines, outperforming them in all cases. By abstaining from predicting non-localizable images, we improve geolocation accuracy from 27.8% to 70.5% at the city-scale, and thus make current geolocation models reliable for real-world applications.
@inproceedings{panagiotopoulos2022selloc, title = {Leveraging Selective Prediction for Reliable Image Geolocation}, author = {Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Patras, Ioannis and Kompatsiaris, Ioannis}, booktitle = {International Conference on Multimedia Modeling (MMM)}, year = {2022}, doi = {10.1007/978-3-030-98355-0_31} } -
 The MeVer DeepFake Detection Service: Lessons Learnt from Developing and Deploying in the WildSpiros Baxevanakis, Giorgos Kordopatis-Zilos, Panagiotis Galopoulos, and 6 more authorsIn International Workshop on Multimedia AI against Disinformation (MAD) @ICMR, 2022
The MeVer DeepFake Detection Service: Lessons Learnt from Developing and Deploying in the WildSpiros Baxevanakis, Giorgos Kordopatis-Zilos, Panagiotis Galopoulos, and 6 more authorsIn International Workshop on Multimedia AI against Disinformation (MAD) @ICMR, 2022New advancements for the detection of synthetic images are critical for fighting disinformation, as the capabilities of generative AI models continuously evolve and can lead to hyper-realistic synthetic imagery at unprecedented scale and speed. In this paper, we focus on the challenge of generalizing across different concept classes, e.g., when training a detector on human faces and testing on synthetic animal images - highlighting the ineffectiveness of existing approaches that randomly sample generated images to train their models. By contrast, we propose an approach based on the premise that the robustness of the detector can be enhanced by training it on realistic synthetic images that are selected based on their quality scores according to a probabilistic quality estimation model. We demonstrate the effectiveness of the proposed approach by conducting experiments with generated images from two seminal architectures, StyleGAN2 and Latent Diffusion, and using three different concepts for each, so as to measure the cross-concept generalization ability. Our results show that our quality-based sampling method leads to higher detection performance for nearly all concepts, improving the overall effectiveness of the synthetic image detectors.
@inproceedings{baxevanakis2022meverdf, title = {The MeVer DeepFake Detection Service: Lessons Learnt from Developing and Deploying in the Wild}, author = {Baxevanakis, Spiros and Kordopatis{-}Zilos, Giorgos and Galopoulos, Panagiotis and Apostolidis, Lazaros and Levacher, Killian and Schlicht, Ipek Baris and Teyssou, Denis and Kompatsiaris, Ioannis and Papadopoulos, Symeon}, booktitle = {International Workshop on Multimedia AI against Disinformation (MAD) @ICMR}, year = {2022}, doi = {10.1145/3512732.3533587}, }



2021
-
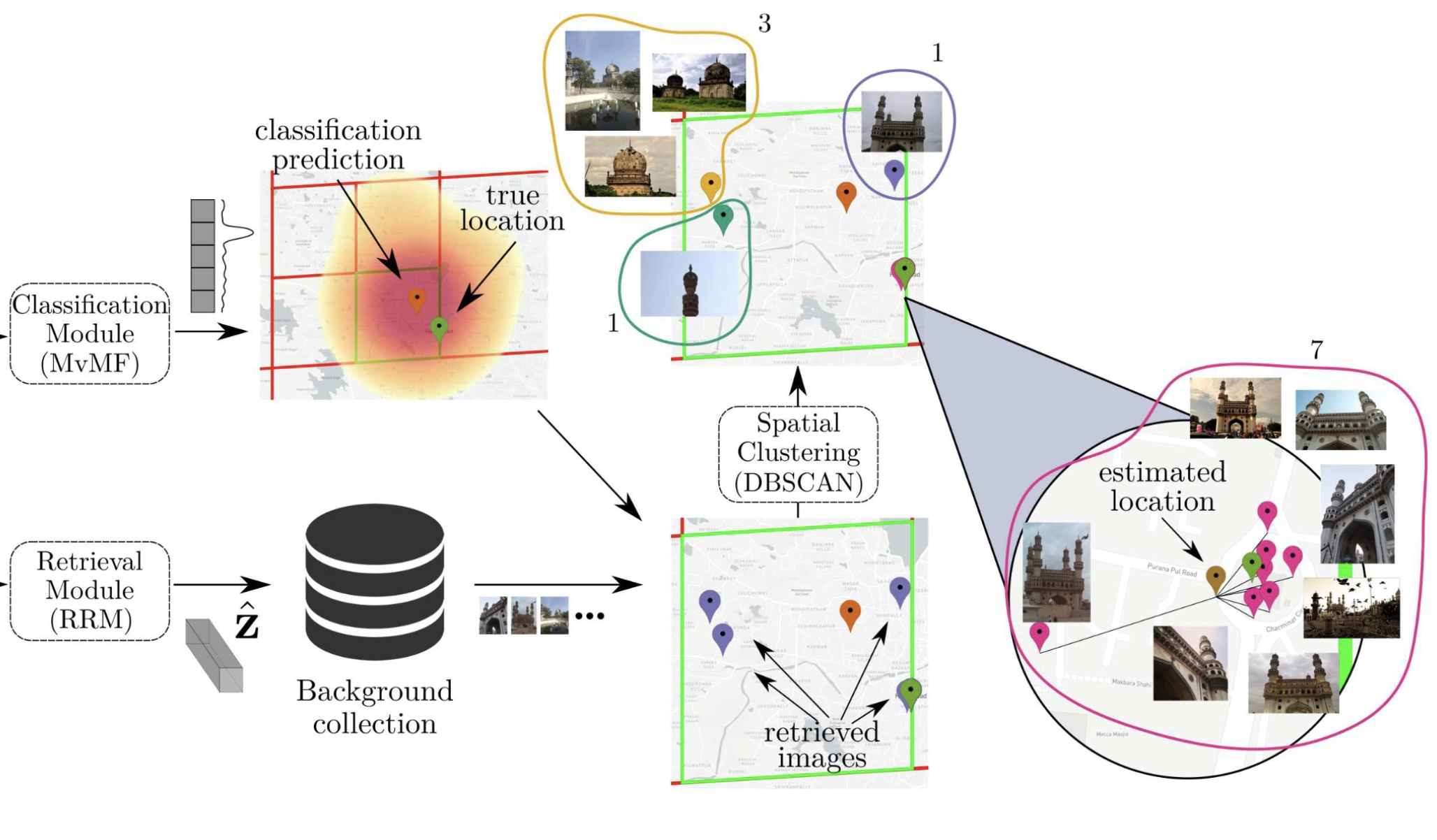 Leveraging EfficientNet and Contrastive Learning for Accurate Global-scale Location EstimationGiorgos Kordopatis-Zilos, Panagiotis Galopoulos, Symeon Papadopoulos, and 1 more authorIn International Conference on Multimedia Retrieval (ICMR), 2021
Leveraging EfficientNet and Contrastive Learning for Accurate Global-scale Location EstimationGiorgos Kordopatis-Zilos, Panagiotis Galopoulos, Symeon Papadopoulos, and 1 more authorIn International Conference on Multimedia Retrieval (ICMR), 2021In this paper, we address the problem of global-scale image geolocation, proposing a mixed classification-retrieval scheme. Unlike other methods that strictly tackle the problem as a classification or retrieval task, we combine the two practices in a unified solution leveraging the advantages of each approach with two different modules. The first leverages the EfficientNet architecture to assign images to a specific geographic cell in a robust way. The second introduces a new residual architecture that is trained with contrastive learning to map input images to an embedding space that minimizes the pairwise geodesic distance of same-location images. For the final location estimation, the two modules are combined with a search-within-cell scheme, where the locations of most similar images from the predicted geographic cell are aggregated based on a spatial clustering scheme. Our approach demonstrates very competitive performance on four public datasets, achieving new state-of-the-art performance in fine granularity scales, i.e., 15.0% at 1km range on Im2GPS3k.
@inproceedings{kordopatis2021loc, title = {Leveraging EfficientNet and Contrastive Learning for Accurate Global-scale Location Estimation}, author = {Kordopatis{-}Zilos, Giorgos and Galopoulos, Panagiotis and Papadopoulos, Symeon and Kompatsiaris, Ioannis}, booktitle = {International Conference on Multimedia Retrieval (ICMR)}, year = {2021}, doi = {10.1145/3460426.3463644}, } -
 Products-6K: a large-scale groceries product recognition datasetKostas Georgiadis, Giorgos Kordopatis-Zilos, Fotis Kalaganis, and 8 more authorsIn PErvasive Technologies Related to Assistive Environments Conference (PETRA), 2021
Products-6K: a large-scale groceries product recognition datasetKostas Georgiadis, Giorgos Kordopatis-Zilos, Fotis Kalaganis, and 8 more authorsIn PErvasive Technologies Related to Assistive Environments Conference (PETRA), 2021Product recognition is a task that receives continuous attention by the computer vision/deep learning community mainly with the scope of providing robust solutions for automatic checkout supermarkets. One of the main challenges is the lack of images that illustrate in realistic conditions a high number of products. Here the product recognition task is perceived slightly differently compared to the automatic checkout paradigm but the challenges encountered are the same. The setting under which this dataset is captured is with the aim to help individuals with visual impairment in doing their daily grocery in order to increase their autonomy. In particular, we propose a large-scale dataset utilized to tackle the product recognition problem in a supermarket environment. The dataset is characterized by (a) large scale in terms of unique products associated with one or more photos from different viewpoints, (b) rich textual descriptions linked to different levels of annotation and, (c) images acquired both in laboratory conditions and in a realistic supermarket scenario portrayed in various clutter and lighting conditions. A direct comparison with existing datasets of this category demonstrates the significantly higher number of the available unique products, as well as the richness of its annotation enabling different recognition scenarios. Finally, the dataset is also benchmarked using various approaches based both on visual and textual descriptors.
@inproceedings{georgiadis2021product6k, title = {Products-6K: a large-scale groceries product recognition dataset}, author = {Georgiadis, Kostas and Kordopatis{-}Zilos, Giorgos and Kalaganis, Fotis and Migkotzidis, Panagiotis and Chatzilari, Elisavet and Panakidou, Valasia and Pantouvakis, Kyriakos and Tortopidis, Savvas and Papadopoulos, Symeon and Nikolopoulos, Spiros and Kompatsiaris, Ioannis}, booktitle = {PErvasive Technologies Related to Assistive Environments Conference (PETRA)}, year = {2021}, doi = {10.1145/3453892.3453894} }


2020
-
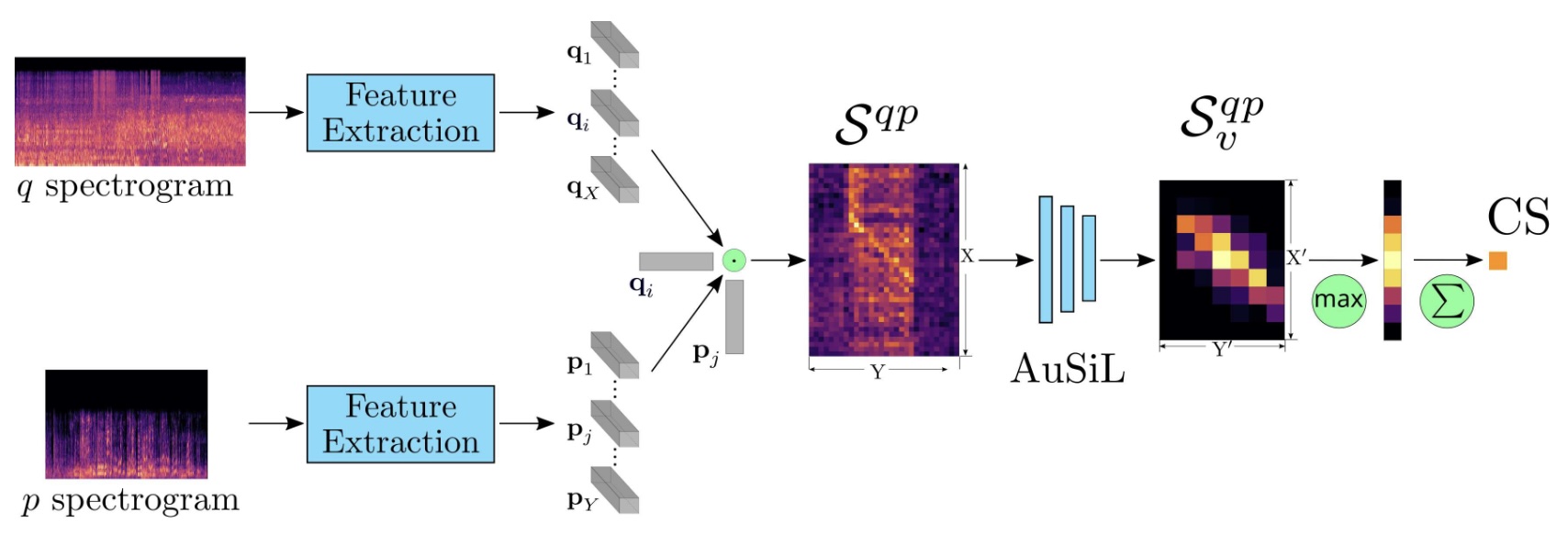 Audio-based Near-Duplicate Video Retrieval with Audio Similarity LearningPavlos Avgoustinakis, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, and 2 more authorsIn International Conference on Pattern Recognition (ICPR), 2020
Audio-based Near-Duplicate Video Retrieval with Audio Similarity LearningPavlos Avgoustinakis, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, and 2 more authorsIn International Conference on Pattern Recognition (ICPR), 2020In this work, we address the problem of audio-based near-duplicate video retrieval. We propose the Audio Similarity Learning (AuSiL) approach that effectively captures temporal patterns of audio similarity between video pairs. For the robust similarity calculation between two videos, we first extract representative audio-based video descriptors by leveraging transfer learning based on a Convolutional Neural Network (CNN) trained on a large scale dataset of audio events, and then we calculate the similarity matrix derived from the pairwise similarity of these descriptors. The similarity matrix is subsequently fed to a CNN network that captures the temporal structures existing within its content. We train our network following a triplet generation process and optimizing the triplet loss function. To evaluate the effectiveness of the proposed approach, we have manually annotated two publicly available video datasets based on the audio duplicity between their videos. The proposed approach achieves very competitive results compared to three state-of-the-art methods. Also, unlike the competing methods, it is very robust to the retrieval of audio duplicates generated with speed transformations.
@inproceedings{avgoustinakis2020ausil, title = {Audio-based Near-Duplicate Video Retrieval with Audio Similarity Learning}, author = {Avgoustinakis, Pavlos and Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Symeonidis, Andreas L. and Kompatsiaris, Ioannis}, booktitle = {International Conference on Pattern Recognition (ICPR)}, year = {2020}, doi = {10.1109/ICPR48806.2021.9413056}, video = {https://www.youtube.com/watch?v=MMHCYS7v-vw} } -
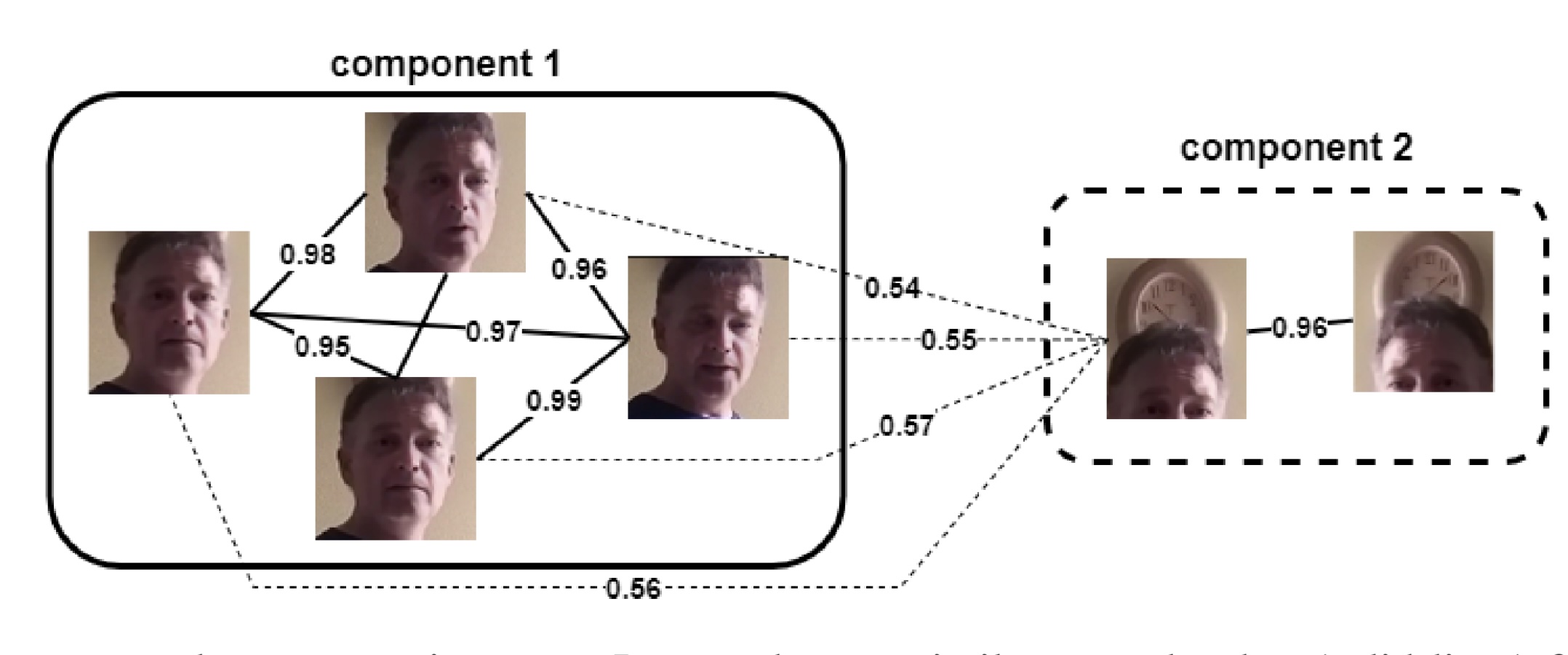 Investigating the Impact of Pre-processing and Prediction Aggregation on the DeepFake Detection TaskPolychronis Charitidis, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, and 1 more authorIn Truth and Trust Online Conference (TTO), 2020
Investigating the Impact of Pre-processing and Prediction Aggregation on the DeepFake Detection TaskPolychronis Charitidis, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, and 1 more authorIn Truth and Trust Online Conference (TTO), 2020Recent advances in content generation technologies (widely known as DeepFakes) along with the online proliferation of manipulated media content render the detection of such manipulations a task of increasing importance. Even though there are many DeepFake detection methods, only a few focus on the impact of dataset preprocessing and the aggregation of frame-level to video-level prediction on model performance. In this paper, we propose a pre-processing step to improve the training data quality and examine its effect on the performance of DeepFake detection. We also propose and evaluate the effect of video-level prediction aggregation approaches. Experimental results show that the proposed pre-processing approach leads to considerable improvements in the performance of detection models, and the proposed prediction aggregation scheme further boosts the detection efficiency in cases where there are multiple faces in a video.
@inproceedings{charitidis2020dfd, title = {Investigating the Impact of Pre-processing and Prediction Aggregation on the DeepFake Detection Task}, author = {Charitidis, Polychronis and Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Kompatsiaris, Ioannis}, booktitle = {Truth and Trust Online Conference (TTO)}, year = {2020} }


2019
-
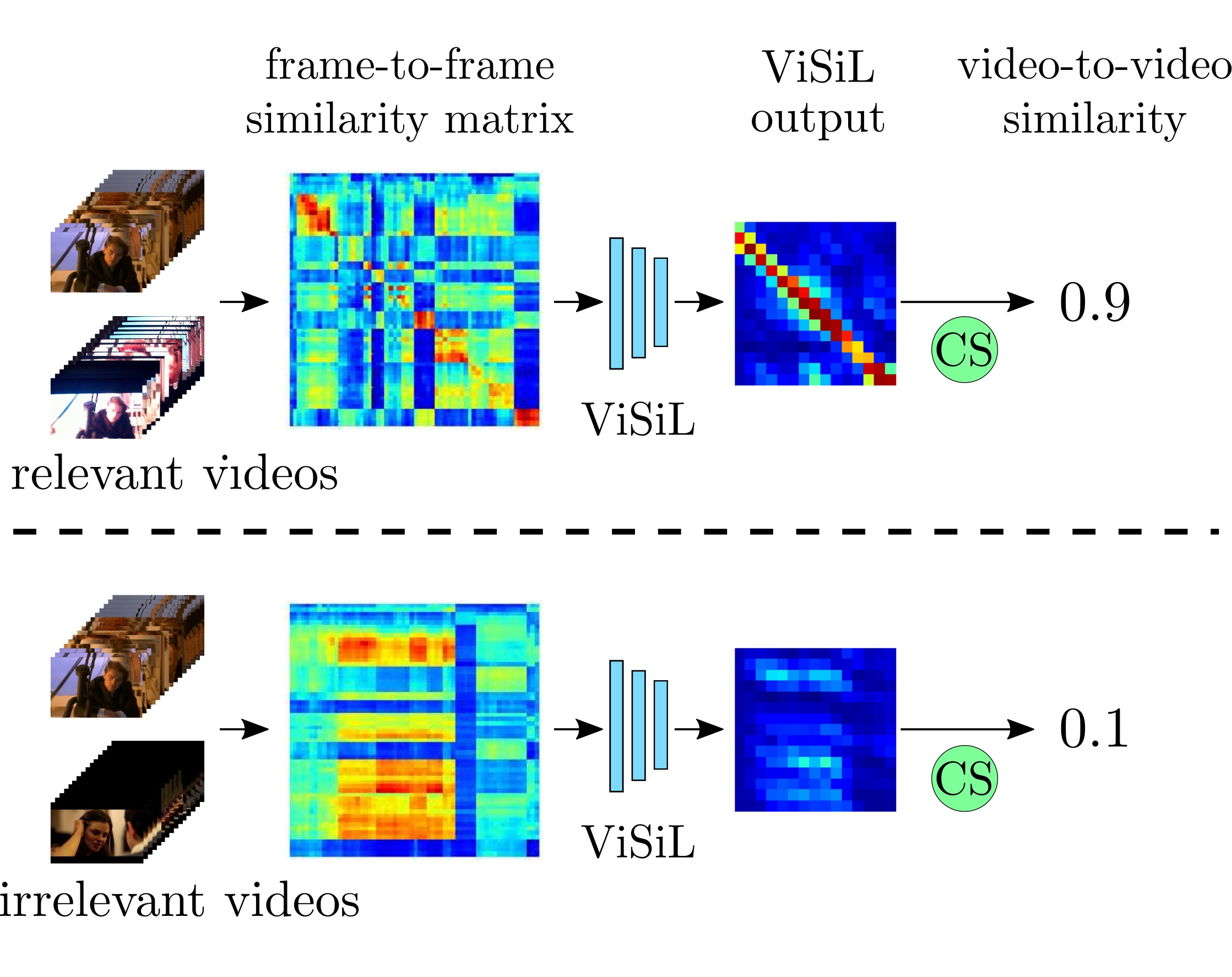 ViSil: Fine-grained Spatio-Temporal Video Similarity LearningGiorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and 1 more authorIn International Conference on Computer Vision (ICCV), 2019
ViSil: Fine-grained Spatio-Temporal Video Similarity LearningGiorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and 1 more authorIn International Conference on Computer Vision (ICCV), 2019In this paper we introduce ViSiL, a Video Similarity Learning architecture that considers fine-grained Spatio-Temporal relations between pairs of videos – such relations are typically lost in previous video retrieval approaches that embed the whole frame or even the whole video into a vector descriptor before the similarity estimation. By contrast, our Convolutional Neural Network (CNN)-based approach is trained to calculate video-to-video similarity from refined frame-to-frame similarity matrices, so as to consider both intra- and inter-frame relations. In the proposed method, pairwise frame similarity is estimated by applying Tensor Dot (TD) followed by Chamfer Similarity (CS) on regional CNN frame features - this avoids feature aggregation before the similarity calculation between frames. Subsequently, the similarity matrix between all video frames is fed to a four-layer CNN, and then summarized using Chamfer Similarity (CS) into a video-to-video similarity score – this avoids feature aggregation before the similarity calculation between videos and captures the temporal similarity patterns between matching frame sequences. We train the proposed network using a triplet loss scheme and evaluate it on five public benchmark datasets on four different video retrieval problems where we demonstrate large improvements in comparison to the state of the art. The implementation of ViSiL is publicly available.
@inproceedings{kordopatis2019visil, title = {{ViSil}: Fine-grained Spatio-Temporal Video Similarity Learning}, author = {Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Patras, Ioannis and Kompatsiaris, Ioannis}, booktitle = {International Conference on Computer Vision (ICCV)}, pages = {6351--6360}, year = {2019}, doi = {10.1109/ICCV.2019.00645}, } -
 FIVR: Fine-grained Incident Video RetrievalGiorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and 1 more authorTransactions on Multimedia (TMM), 2019
FIVR: Fine-grained Incident Video RetrievalGiorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and 1 more authorTransactions on Multimedia (TMM), 2019This paper introduces the problem of Fine-grained Incident Video Retrieval (FIVR). Given a query video, the objective is to retrieve all associated videos, considering several types of associations that range from duplicate videos to videos from the same incident. FIVR offers a single framework that contains several retrieval tasks as special cases. To address the benchmarking needs of all such tasks, we construct and present a large-scale annotated video dataset, which we call FIVR-200K, and it comprises 225,960 videos. To create the dataset, we devise a process for the collection of YouTube videos based on major news events from recent years crawled from Wikipedia and deploy a retrieval pipeline for the automatic selection of query videos based on their estimated suitability as benchmarks. We also devise a protocol for the annotation of the dataset with respect to the four types of video associations defined by FIVR. Finally, we report the results of an experimental study on the dataset comparing five state-of-the-art methods developed based on a variety of visual descriptors, highlighting the challenges of the current problem.
@article{kordopatis2019fivr, title = {FIVR: Fine-grained Incident Video Retrieval}, author = {Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Patras, Ioannis and Kompatsiaris, Ioannis}, journal = {Transactions on Multimedia (TMM)}, volume = {21}, number = {10}, pages = {2638--2652}, year = {2019}, doi = {10.1109/TMM.2019.2905741}, video = {https://www.youtube.com/watch?v=Ku9oeS_al5w} }


2018
-
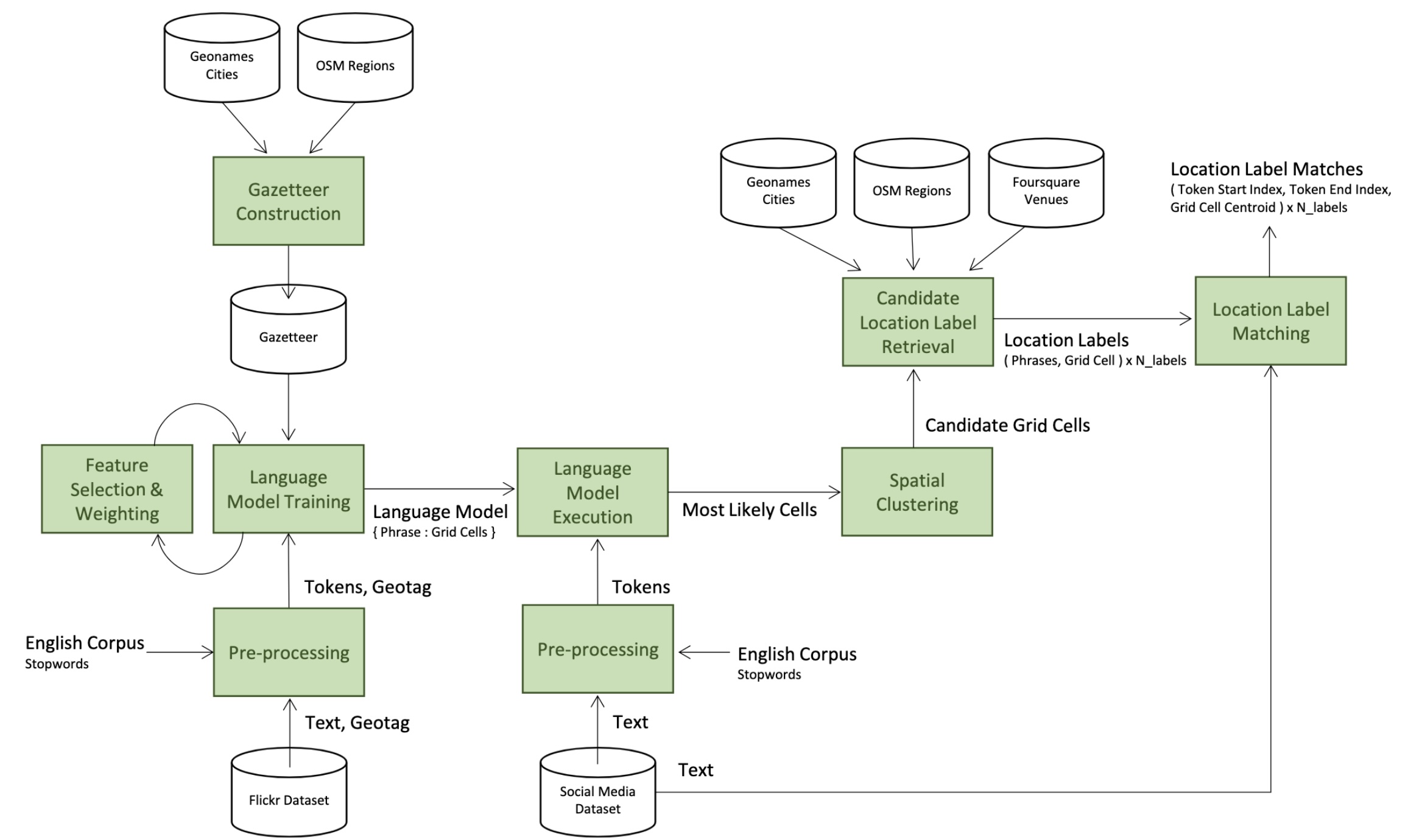 Location Extraction from Social Media: Geoparsing, Location Disambiguation and GeotaggingStuart E. Middleton, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, and 1 more authorTransactions on Information Systems (ToIS), 2018
Location Extraction from Social Media: Geoparsing, Location Disambiguation and GeotaggingStuart E. Middleton, Giorgos Kordopatis-Zilos, Symeon Papadopoulos, and 1 more authorTransactions on Information Systems (ToIS), 2018Location extraction, also called “toponym extraction,” is a field covering geoparsing, extracting spatial representations from location mentions in text, and geotagging, assigning spatial coordinates to content items. This article evaluates five “best-of-class” location extraction algorithms. We develop a geoparsing algorithm using an OpenStreetMap database, and a geotagging algorithm using a language model constructed from social media tags and multiple gazetteers. Third-party work evaluated includes a DBpedia-based entity recognition and disambiguation approach, a named entity recognition and Geonames gazetteer approach, and a Google Geocoder API approach. We perform two quantitative benchmark evaluations, one geoparsing tweets and one geotagging Flickr posts, to compare all approaches. We also perform a qualitative evaluation recalling top N location mentions from tweets during major news events. The OpenStreetMap approach was best (F1 0.90+) for geoparsing English, and the language model approach was best (F1 0.66) for Turkish. The language model was best (F1@1km 0.49) for the geotagging evaluation. The map database was best (R@20 0.60+) in the qualitative evaluation. We report on strengths, weaknesses, and a detailed failure analysis for the approaches and suggest concrete areas for further research.
@article{middleton2018lesm, title = {Location Extraction from Social Media: Geoparsing, Location Disambiguation and Geotagging}, author = {Middleton, Stuart E. and Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Kompatsiaris, Ioannis}, journal = {Transactions on Information Systems (ToIS)}, volume = {36}, number = {40}, pages = {1--27}, year = {2018}, doi = {10.1145/3202662} }

2017
-
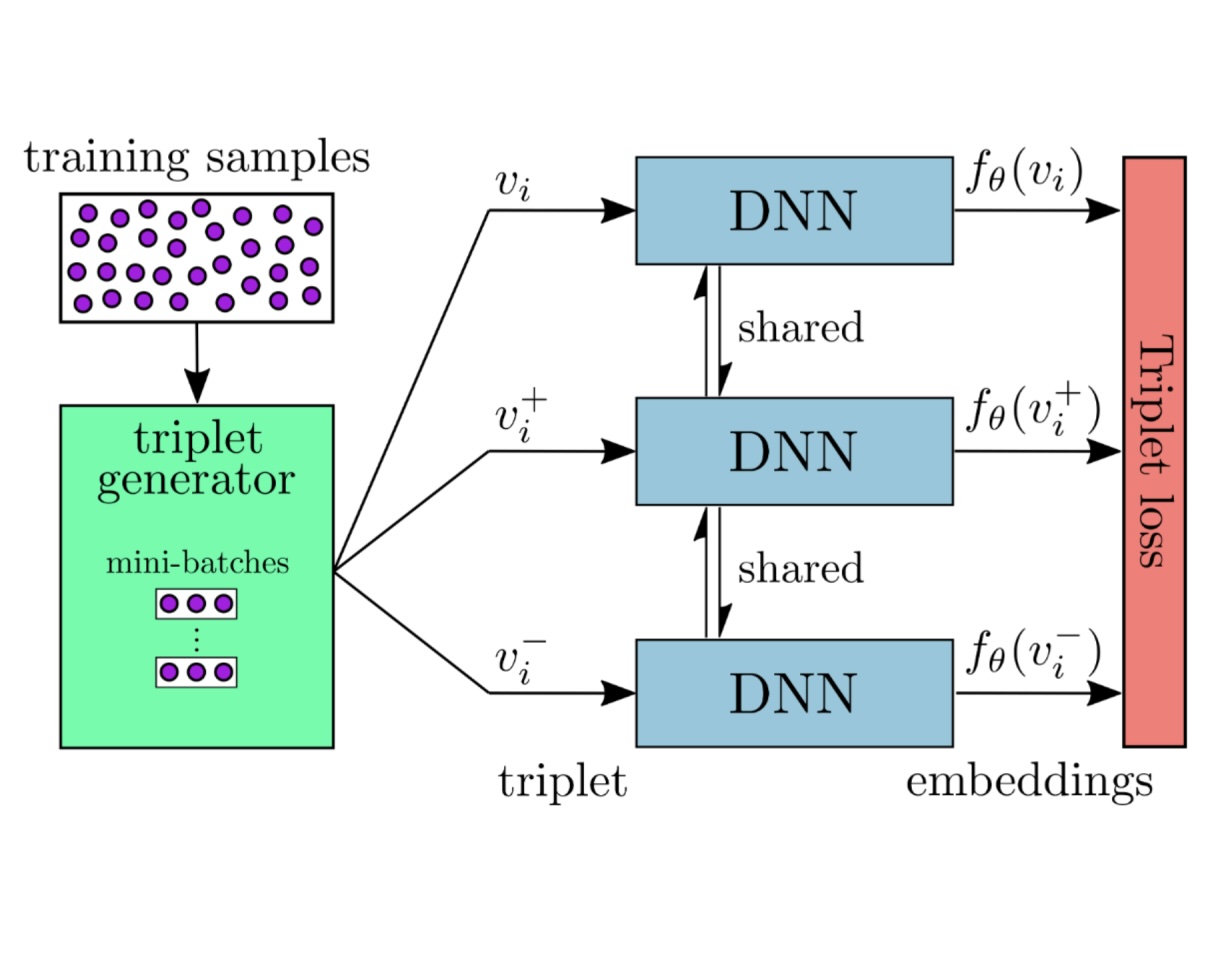 Near-Duplicate Video Retrieval With Deep Metric LearningGiorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and 1 more authorIn International Conference on Computer Vision Workshops (ICCVW), 2017
Near-Duplicate Video Retrieval With Deep Metric LearningGiorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and 1 more authorIn International Conference on Computer Vision Workshops (ICCVW), 2017This work addresses the problem of Near-Duplicate Video Retrieval (NDVR). We propose an efficient video-level NDVR scheme based on deep metric learning that leverages CNN features from intermediate layers to generate discriminative global video representations in tandem with a Deep Metric Learning (DML) framework with two fusion variations, trained to approximate an embedding function for accurate distance calculation between two near-duplicate videos. In contrast to most state-of-the-art methods, which exploit information deriving from the same source of data for both development and evaluation (which usually results to dataset-specific solutions), the proposed model is fed during training with sampled triplets generated from an independent dataset and is thoroughly tested on the widely used CC_WEB_VIDEO dataset. We demonstrate that the proposed approach achieves outstanding performance against the state-of-the-art, either with or without access to the evaluation dataset.
@inproceedings{kordopatis2017dml, title = {Near-Duplicate Video Retrieval With Deep Metric Learning}, author = {Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Patras, Ioannis and Kompatsiaris, Ioannis}, booktitle = {International Conference on Computer Vision Workshops (ICCVW)}, year = {2017}, doi = {10.1109/ICCVW.2017.49} } -
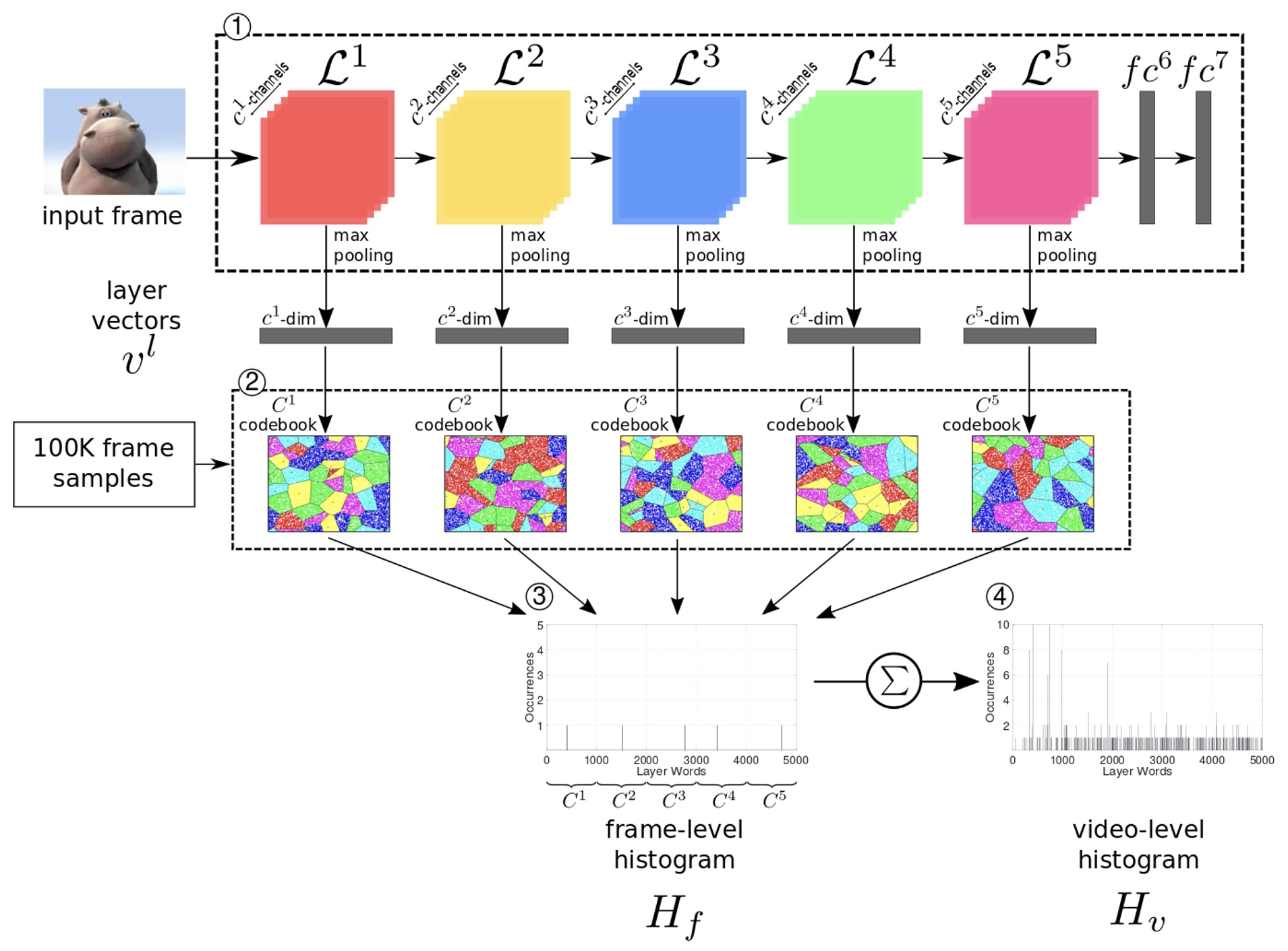 Near-Duplicate Video Retrieval by Aggregating Intermediate CNN LayersGiorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and 1 more authorIn International Conference on Multimedia Modeling (MMM), 2017
Near-Duplicate Video Retrieval by Aggregating Intermediate CNN LayersGiorgos Kordopatis-Zilos, Symeon Papadopoulos, Ioannis Patras, and 1 more authorIn International Conference on Multimedia Modeling (MMM), 2017The problem of Near-Duplicate Video Retrieval (NDVR) has attracted increasing interest due to the huge growth of video content on the Web, which is characterized by high degree of near duplicity. This calls for efficient NDVR approaches. Motivated by the outstanding performance of Convolutional Neural Networks (CNNs) over a wide variety of computer vision problems, we leverage intermediate CNN features in a novel global video representation by means of a layer-based feature aggregation scheme. We perform extensive experiments on the widely used CC_WEB_VIDEO dataset, evaluating three popular deep architectures (AlexNet, VGGNet, GoogLeNet) and demonstrating that the proposed approach exhibits superior performance over the state-of-the-art, achieving a mean Average Precision (mAP) score of 0.976.
@inproceedings{kordopatis2017lbow, title = {Near-Duplicate Video Retrieval by Aggregating Intermediate CNN Layers}, author = {Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Patras, Ioannis and Kompatsiaris, Ioannis}, booktitle = {International Conference on Multimedia Modeling (MMM)}, year = {2017}, doi = {10.1007/978-3-319-51811-4_21} } -
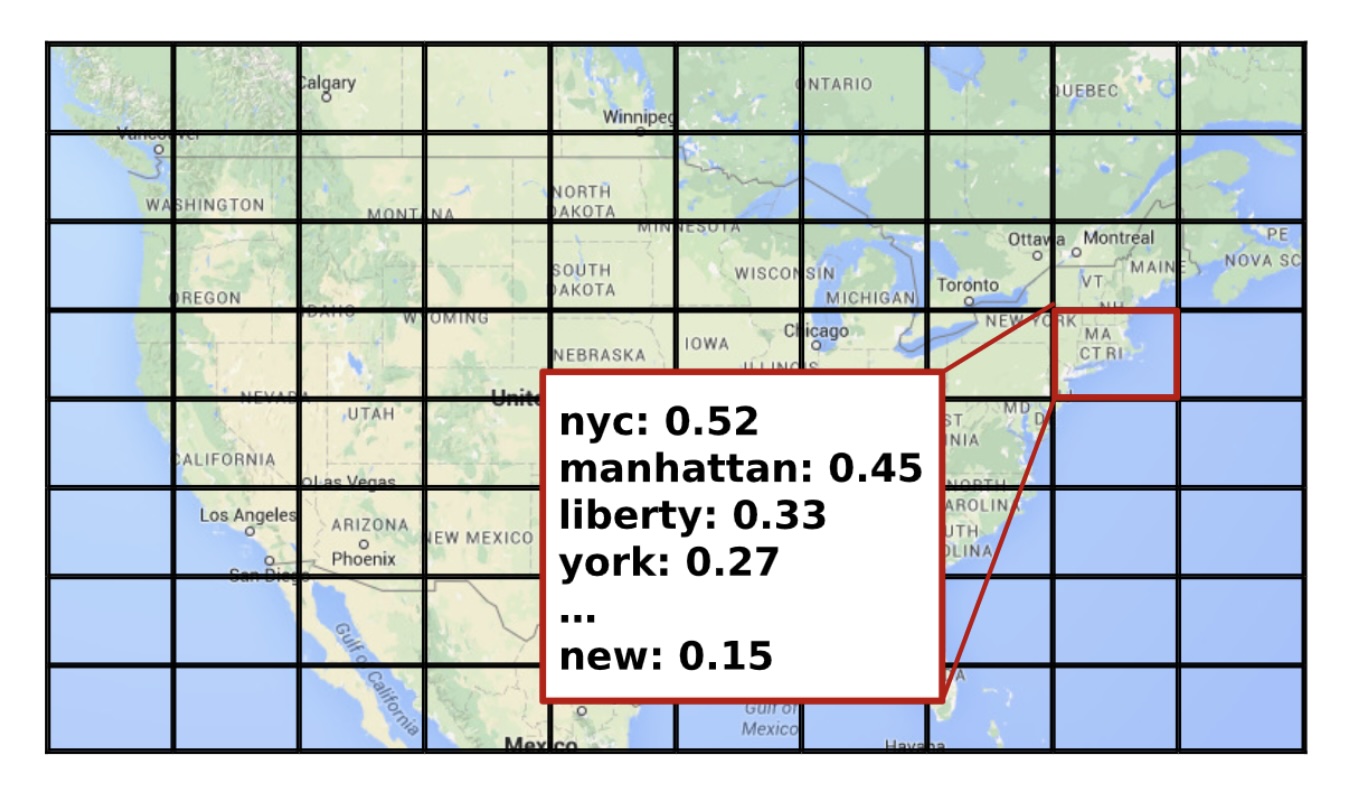 Geotagging Text Content with Language Models and Feature MiningGiorgos Kordopatis-Zilos, Symeon Papadopoulos, and Ioannis KompatsiarisProceedings of IEEE (PoIEEE), 2017
Geotagging Text Content with Language Models and Feature MiningGiorgos Kordopatis-Zilos, Symeon Papadopoulos, and Ioannis KompatsiarisProceedings of IEEE (PoIEEE), 2017The large-scale availability of user-generated content in social media platforms has recently opened up new possibilities for studying and understanding the geospatial aspects of real-world phenomena and events. Yet, the large majority of user-generated content lacks proper geographic information (in the form of latitude and longitude coordinates). As a result, the problem of multimedia geotagging, i.e., extracting location information from user-generated text items when this is not explicitly available, has attracted increasing research interest. Here, we present a highly accurate geotagging approach for estimating the locations alluded by text annotations based on refined language models that are learned from massive corpora of social media annotations. We further explore the impact of different feature selection and weighting techniques on the performance of the approach. In terms of evaluation, we employ a large benchmark collection from the MediaEval Placing Task over several years. We demonstrate the consistently superior geotagging accuracy and low median distance error of the proposed approach using various data sets and comparing it against a number of state-of-the-art systems.
@article{kordopatis2017geotag, title = {Geotagging Text Content with Language Models and Feature Mining}, author = {Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Kompatsiaris, Ioannis}, journal = {Proceedings of IEEE (PoIEEE)}, volume = {105}, number = {10}, pages = {1971--1986}, year = {2017}, doi = {10.1109/JPROC.2017.2688799} }



2016
-
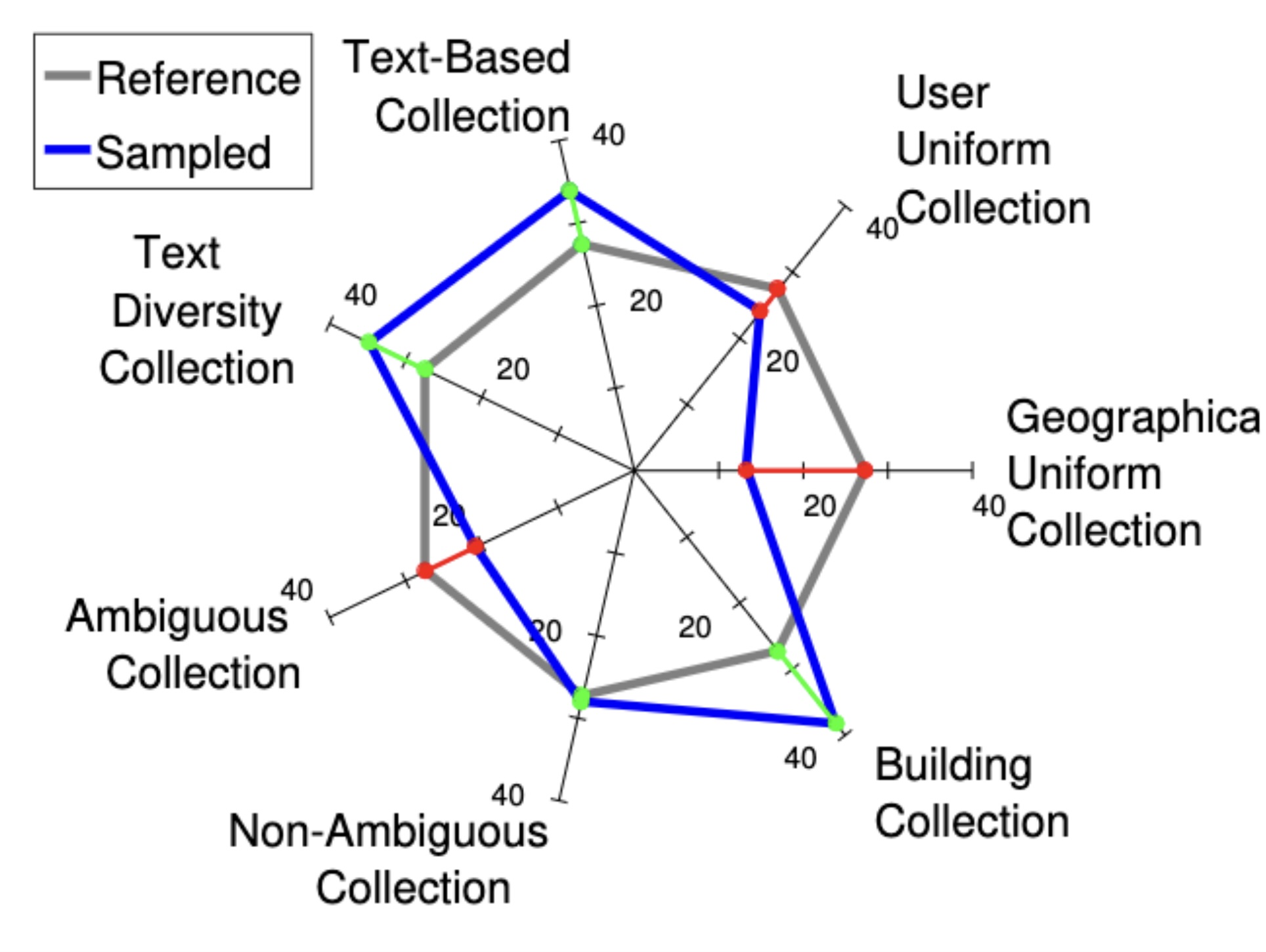 In-depth Exploration of Geotagging Performance using Sampling Strategies on YFCC100MGiorgos Kordopatis-Zilos, Symeon Papadopoulos, and Ioannis KompatsiarisIn ACM Workshop on Multimedia COMMONS @ACMMM, 2016
In-depth Exploration of Geotagging Performance using Sampling Strategies on YFCC100MGiorgos Kordopatis-Zilos, Symeon Papadopoulos, and Ioannis KompatsiarisIn ACM Workshop on Multimedia COMMONS @ACMMM, 2016Evaluating multimedia analysis and retrieval systems is a highly challenging task, of which the outcomes can be highly volatile depending on the selected test collection. In this paper, we focus on the problem of multimedia geotagging, i.e. estimating the geographical location of a media item based on its content and metadata, in order to showcase that very different evaluation outcomes may be obtained depending on the test collection at hand. To alleviate this problem, we propose an evaluation methodology based on an array of sampling strategies over a reference test collection, and a way of quantifying and summarizing the volatility of performance measurements. We report experimental results on the MediaEval 2015 Placing Task dataset, and demonstrate that the proposed methodology could help capture the performance of geotagging systems in a comprehensive manner that is complementary to existing evaluation approaches.
@inproceedings{kordopatis2016geotag, title = {In-depth Exploration of Geotagging Performance using Sampling Strategies on YFCC100M}, author = {Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Kompatsiaris, Ioannis}, booktitle = {ACM Workshop on Multimedia COMMONS @ACMMM}, year = {2016}, doi = {10.1145/2983554.2983558} }

2015
-
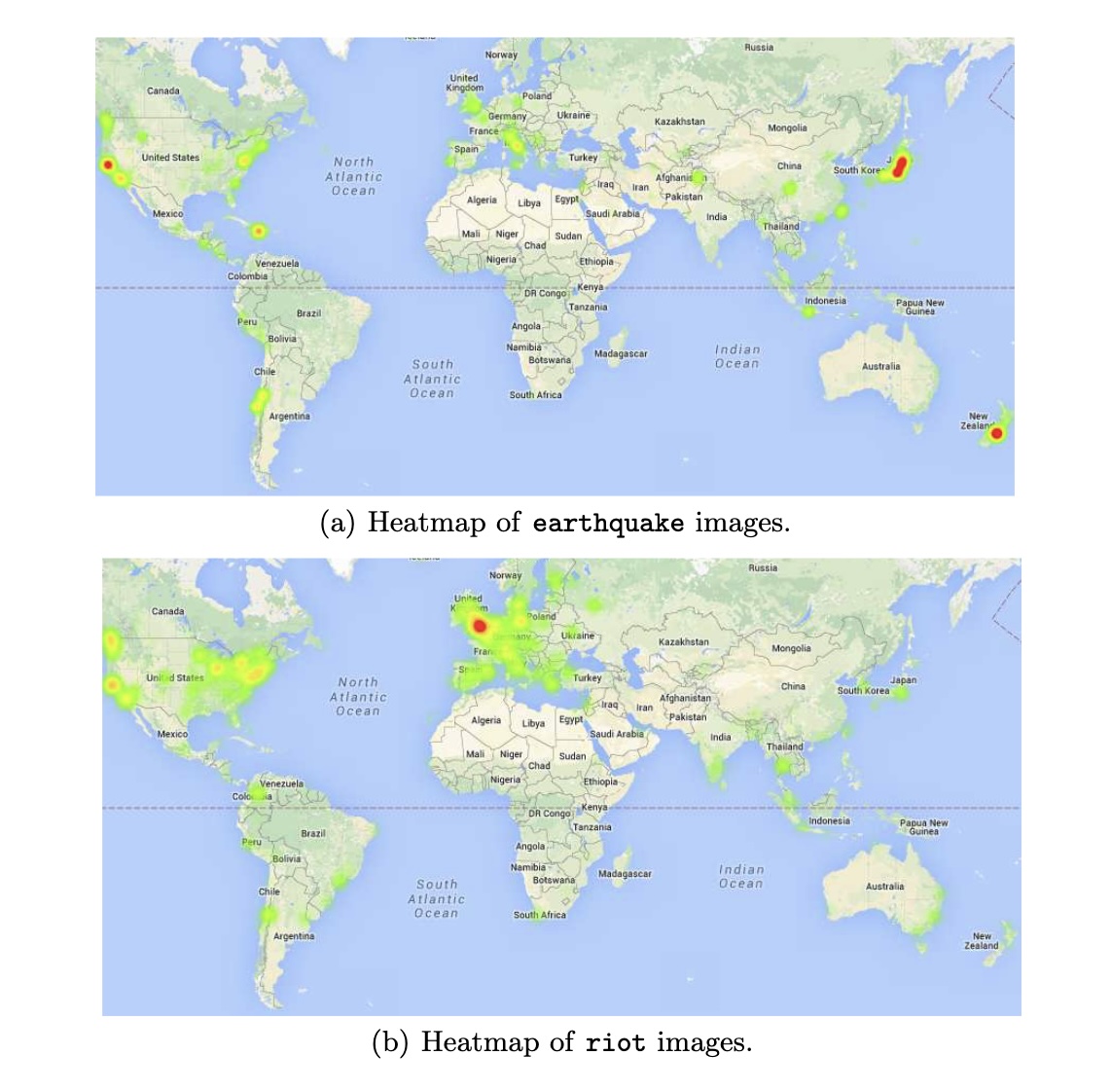 Geotagging Social Media Content with a Refined Language Modelling ApproachGiorgos Kordopatis-Zilos, Symeon Papadopoulos, and Ioannis KompatsiarisIn Pacific-Asia Workshop on Intelligence and Security Informatics (PAISI) @PAKDD, 2015
Geotagging Social Media Content with a Refined Language Modelling ApproachGiorgos Kordopatis-Zilos, Symeon Papadopoulos, and Ioannis KompatsiarisIn Pacific-Asia Workshop on Intelligence and Security Informatics (PAISI) @PAKDD, 2015The problem of content geotagging, i.e. estimating the geographic position of a piece of content (text message, tagged image, etc.) when this is not explicitly available, has attracted increasing interest as the large volumes of user-generated content posted through social media platforms such as Twitter and Instagram form nowadays a key element in the coverage of news stories and events. In particular, in large-scale incidents, where location is an important factor, such as natural disasters and terrorist attacks, a large number of people around the globe post comments and content to social media. Yet, the large majority of content lacks proper geographic information (in the form of latitude and longitude coordinates) and hence cannot be utilized to the full extent (e.g., by viewing citizens reports on a map). To this end, we present a new geotagging approach that can estimate the location of a post based on its text using refined language models that are learned from massive corpora of social media content. Using a large benchmark collection, we demonstrate the improvements in geotagging accuracy as a result of the proposed refinements.
@inproceedings{kordopatis2015geotag, title = {Geotagging Social Media Content with a Refined Language Modelling Approach}, author = {Kordopatis{-}Zilos, Giorgos and Papadopoulos, Symeon and Kompatsiaris, Ioannis}, booktitle = {Pacific-Asia Workshop on Intelligence and Security Informatics (PAISI) @PAKDD}, year = {2015}, doi = {10.1007/978-3-319-18455-5_2} }
